
Here’s a common scenario, you have an application running which has some sort of AI features.
This could be a custom application that you or the team built or even a third party application or a combination of these.
Does this mean that your work is now complete?
Not quite… There is more to this.
Of-course as part of operational excellence or day 2 activities, you need to look at maintaining your AI workload.
But what exactly constitutes an AI workload especially as there are different ways to consume it than just your standard compute and storage and pay as you go pricing of cloud-managed services that we’re used to?
And why is the finance team suddenly yelling at me for overstepping my allocated budget?
As an Engineer, does it even matter? Isn’t it enough if you just build some cool stuff?
I used to think exactly like that, as the cost stuff was the “boring part”. Every time cost or governance was mentioned, I tuned out, because it wasn’t like you got to talk about the new shiny tool that I could use.
Since going over to a more senior role, I realised that there is more to just cool technical tools.
Especially with the influx of new AI tooling after a good 2 years since the whole generative AI craze, I could now see many teams within organisations struggling with the spike in Proof of Concept costs that didn’t get productionised. Where in fact, was the Return On Investment?
And where would you typically start in this case?
Start small and define your AI workload for your use case and make this visible.
At least that’s what the FinOps organisation says about AI workloads.
For a comprehensive approach of how to start making your costs visible across your AI workloads, this article from the official FinOps org has some practical tips.
You may be wondering if you’ve read this far, I get the FinOps part, but what’s that got to do with drones?
Now you may have noticed that this is part 2 of the blog and part 1 is available here which talks more about where drones fit in.
As a refresher, the app that was built then was around using images collected by drones for predictive maintenance with the help of multi-modal LLMs orchestrated by AI agents on AWS.
Let’s say you need to now add some FinOps features for this workload, albeit in this case across AWS.
In reality, it may be a little more complex, as you may have systems outside of 1 cloud hyperscaler with multiple SaaS and other systems on other hyperscalers or even on-premises.
I added the FinOps functionality, using the FinOps v2.0 standard as per video below.
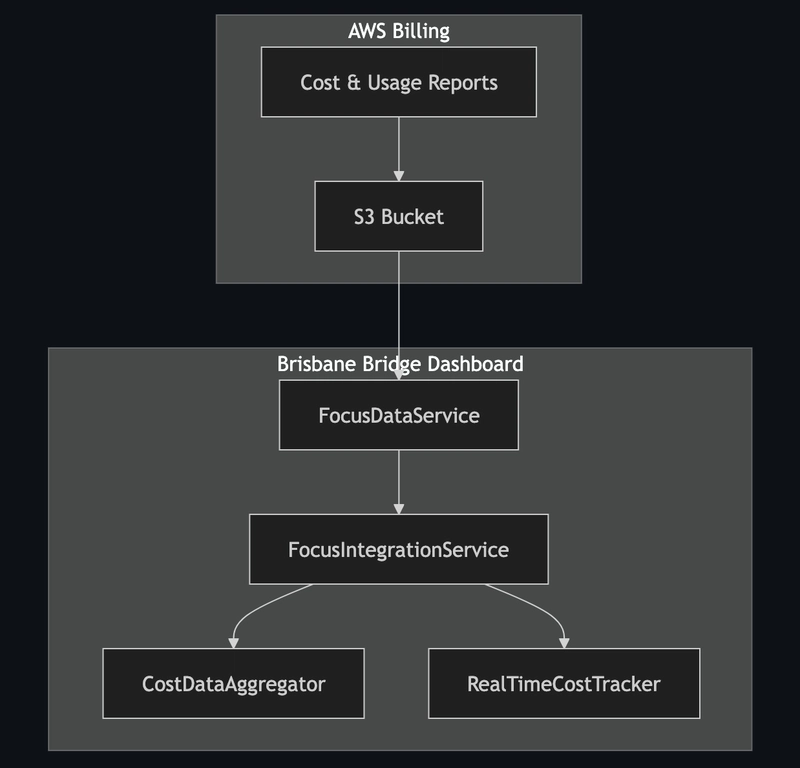
I’ve asked Kiro which is AWS’s spec-driven code generation tool to help me add the FinOps functionality, within the Brisbane Bridge Dashboard front end page.
The initial design was this logical architecture. In order to get real-time AWS Cost and Usage Report (CUR) data, there was a lot of moving parts that was inefficient.

Kiro did try to get real CUR data from my AWS account but failed despite a number of steers.
While pondering about the next step to resolve this issue, I remembered how you can integrate any MCP servers with Kiro.
I configured the official AWS Cost Explorer MCP server with Kiro to take out the guess work.
Super useful to have the following tools which align to the first step in FinOps to gain visibility of your AI workloads via tags.
Let’s take a look at how this panned out when I asked Amazon’s Kiro to help me add this functionality on the dashboard.
You can see in the dashboard it gives you an overview of what the overall spend is, and what the Return On Investment is and the cost savings are based on factoring the AI workload in this case all on AWS which includes the following for this specific app: (YMMV – Your Mileage May Vary)
- 1. Generative AI/LLMs/Agents – Amazon Bedrock including Bedrock Agents – Claude and Nova models Tokens in and out, other pay per use costs
- 2. Storage associated with this workload – Amazon S3
- 3. Compute associated with this workload – AWS Lambda functions
- 4. Databases associated with this workload – AWS DynamoDB
- 5. Other AWS-managed services costs – Amazon API Gateway, Amazon CloudFront
- 6. Other Networking costs – data transfer costs over 100GB
In a real-life scenario, you would also need to factor in any SaaS usage and licensing costs e.g. other LLMs from other hyperscalers, HuggingFace, Snowflake or Databricks for your data or other AI/ML, observability, security and governance related systems related to this workload too.
From an orchestration standpoint, do you use Apache Airflow, Kubeflow, other CI/CD costs.
Maybe additional compute might be used like some containers with Amazon EKS or ECS. There might also be some Spot capacity used for batch processing.
What about if you incorporate some additional AI services like Amazon Textract, Amazon Comprehend etc? That’s another part that needs to be considered.
Not to mention if using RAG or CAG, your vector database costs including Amazon Bedrock Knowledgebases or Amazon OpenSearch for the Vector Database component in RAG.
For CAG, you might be looking at Amazon ElastiCache or Amazon API Gateway.
How would you calculate Fine-tuning costs?
What if you replicate data across multiple AWS regions starting with Amazon S3? What if your AI workload is so critical that it’s active-active?
How about if there’s spikes in usage with anomalies where the token counts go up and the context size increases unexpectedly? Are you prepared for the cost blowout?
If you think that’s too much for one cloud environment, we also can’t forget that many have AI workloads spanning multiple-clouds and on-premises as well.
Some may even have most of their core data on-premises and may want to run their inference close to their data. Now do we need to consider egress costs from the hyperscalers out?
This may sound very overwhelming and the first step is to start with the use case and agree on which components should be included for a small use case.
This includes all of these personas according to the FinOps article.

Getting alignment with the above teams is the most difficult part of the process, solving the technical part of the challenge is easy.
Keen to hear how you’ve solved how to get alignment on what an “AI workload” means for your use case and organisation?
