- The exam itself is a bit easier than the MLS one — some questions can be answered at a glance.
- Around 60%–80% of the questions focus on SageMaker.
- Below are my summarised notes from this attempt — I hope they can help anyone preparing for the exam in the future.
🧠 SageMaker Overview
Data Wrangler
- Provides a user-friendly interface to clean, preprocess, and transform data without needing to write custom code.
- Includes built-in transformations to balance data, such as Random Oversampler/Undersampler and SMOTE (Synthetic Minority Over-sampling Technique).
Autopilot
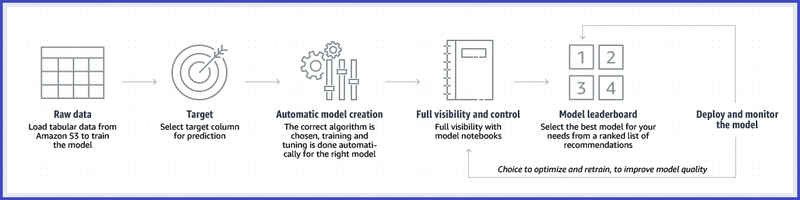
- Automates the process of building and deploying machine learning models.

Clarify
- Identifies potential bias during data preparation and explains predictions without needing custom code.
Debugger
- Provides tools to register hooks and callbacks to extract model output tensors.
- Offers built-in rules to detect model convergence issues such as overfitting, underutilized GPU, and vanishing/exploding gradients.
Feature Attribution Drift
- Use the ModelExplainabilityMonitor class to generate a feature attribution baseline and deploy a monitoring mechanism that evaluates whether feature attribution drift has occurred.
- Then deploy the baseline to SageMaker Model Monitor.
Learn more →
Shadow Testing
- Enables testing of new ML models against production models using live data without impacting live inference traffic.
- Helps identify potential configuration errors, performance issues, and other problems before full deployment.
Neo
- Enables machine learning models to train once and run anywhere — both in the cloud and at the edge.
JumpStart
- A machine learning hub with prebuilt models and solutions.
Ground Truth
- Provides labeling workflows for creating high-quality training datasets.
FSx for Lustre
- Designed for large-scale ML training and HPC workloads.
- Can be linked directly to an S3 bucket, caching data as needed.
- Requires minimal setup.
ML Lineage Tracking
- Creates and stores metadata about ML workflow steps from data preparation to model deployment.
- Enables reproducibility, model governance, and audit tracking.
Canvas
- Allows users to import, prepare, transform, visualize, and analyze data using a visual interface.
📊 Model Monitoring in SageMaker
SageMaker Model Monitor provides the following types of monitoring:
- Data Quality – Monitor drift in data quality.
- Model Quality – Monitor drift in model metrics such as accuracy.
- Bias Drift – Monitor bias in model predictions.
-
Feature Attribution Drift – Monitor changes in feature attribution.
-
SageMaker Endpoints can enable data capture and reuse that data for retraining.
-
Bring Your Own Containers (BYOC) — e.g., deploy ML models built with R.
-
Network Isolation — blocks internet and external network access.
-
Asynchronous Inference — suitable for large payloads (up to 1 GB) and long processing times (up to 1 hour).
Auto-scales to zero when idle, reducing costs.
-
Batch Transform — perform inference without persistent endpoints.
-
Real-Time Inference — supports payloads up to 5 MB for synchronous requests.
⚖️ Model Explainability & Bias Detection
-
Difference in Proportions of Labels (DPL) — detects pre-training bias to prevent discriminatory models.
-
Partial Dependence Plots (PDPs) — illustrate how predictions change with one input feature.
-
Shapley Values — determine the contribution of each feature to model predictions.
🧩 Other SageMaker Features
-
TensorBoard Integration — visualize the training process and debug model performance.
-
Feature Store — create feature groups, ingest records, and build datasets for training.
-
Managed Warm Pools — retain and reuse infrastructure after training jobs to reduce latency for iterative workloads.
-
Inference Recommender — automates load testing and helps select the best instance configuration for ML workloads.
🔍 Other AWS Services & Concepts
OpenSearch
- Can be used as a Vector Database.
Docs →
Data Augmentation
- Generates synthetic data to improve model training and reduce overfitting.
Docs → - Benefits:
- Enhanced model performance
- Reduced data dependency
- Mitigates overfitting
AppFlow
- Fully managed integration service for secure data transfer between SaaS apps (e.g., Salesforce, SAP, Google Analytics) and AWS (e.g., S3, Redshift).
Forecast
- Handles missing values in time-series forecasting.
Docs →
Glue
- ETL service for preparing and transforming data.
DataBrew
- Visual data preparation tool with data quality rules, cleaning, and feature engineering.
🗣️ AI/ML Application Services
| Service | Description |
|---|---|
| Lex | Chatbot and call center solutions |
| Polly | Text-to-speech service |
| Transcribe | Speech-to-text |
| Forecast | Time-series forecasting |
| Rekognition | Image and video analysis (object detection, facial recognition) |
| Comprehend | NLP for sentiment analysis, topic modeling, and PII redaction |
| Kendra | Intelligent enterprise search with GenAI Index for RAG and digital assistants |
| Bedrock | Managed API access to LLMs like Jurassic-2 |
| Managed Service for Apache Flink | Fully managed real-time stream processing service (supports anomaly detection with RANDOM_CUT_FOREST) |
🧩 General ML Concepts
- Embeddings — high-dimensional vectors capturing semantic meaning.
- RAG (Retrieval-Augmented Generation) — enriches responses with external knowledge sources.
- Temperature — controls randomness of generative model output (low = focused, high = creative).
- Top_k — limits token choices to top k probabilities; higher values increase diversity.
- Recall — focuses on minimizing false negatives.
- Precision — focuses on minimizing false positives.
- Concept Drift — when data patterns change over time, degrading model accuracy.
- MAE (Mean Absolute Error) — measures the average magnitude of prediction errors.
- Learning Rate — controls training step size; too high overshoots, too low slows convergence.
- Trainium Chips — AWS-built AI chips for efficient model training and inference.
📈 Performance Metrics
Common evaluation metrics for ML models:
- Precision
- Recall
- Accuracy
- F1 Score
- ROC
- AUC
- RMSE
- MAPE