
On May 8, 2025, the enthusiasm at AWS Summit Bangalore was apparent. I knew I was going to have a thought-provoking day at the summit’s Technical Edition as soon as I entered the KTPO Exhibition Center in Whitefield. Unexpectedly, one session would fundamentally alter my viewpoint on cloud-based High-Performance Computing (HPC).
Traditional on-premises data centers have a set capacity limit, which was a strong point made at the beginning of the session. You spend a lot of money on infrastructure that suffers during moments of high strain but remains inactive during times of low demand. The contrast was startling: AWS provides elasticity and a dynamic ecosystem of services, whereas on the other side you have limited capacity with delays and engineering bottlenecks.
What drew my attention, though, is that firms experience $507 in additional revenues and $47 in additional profit for every $1 spent on HPC. That is transformative, not simply amazing. The ability to scale computing resources precisely when needed, without the requirement for drawn-out purchasing cycles or significant capital expenditures, is what provides this return on investment.
We were shown a thorough seven-layer HPC tech stack by the presenters:
-
Environment Layer: VPC, VPN, AWS Direct Connect, subnets, gateways, cost management, and governance
-
Compute Layer: EC2 instances, AWS Nitro, and Elastic Fabric Adapter for ultra-low latency networking
-
Storage Layer: Amazon FSx, EBS, S3, and EFS for different performance needs
-
Orchestration Layer: AWS ParallelCluster for managing HPC workloads
-
Visualization Layer: AWS NICE DCV for remote desktop and visualization
-
User Portal Layer: AWS Research and Engineering Studio for simplified access
-
ML4Sim Layer: UNET, MeshGraphNet, and Physics Informed Neural Networks (PINN) for ML-enhanced simulations
This multi-layered strategy offers flexibility while preserving the comfort that HPC users are used to.
AWS provides computing choices based on particular workload characteristics:
Performance-focused options:
- Instances with optimized memory and computation for simulations involving large amounts of data
- Instances of graphics and rendering for visualization workloads
- High clock speed instances for single-threaded applications
- Accelerated computing for GPU-intensive tasks
Cost-focused pricing models:
- On-demand: Pay by the second with zero commitments
- Savings Plans and Reserved Instances: Save up to 72% with commitments
- Spot Instances: Leverage spare EC2 capacity at up to 90% off on-demand prices
Because of this flexibility, you can adjust your setup to suit the needs of each job, optimizing for both performance and cost.
The talk demonstrated how HPC is used in many different industries:
- Automotive: Building designs faster with computational fluid dynamics (CFD) simulations
- Pharmaceuticals: Fast-tracking drug discovery and structure-based drug design
- Genomics: Advancing insights using predictive, real-time, or retrospective data applications
- Energy: Running geoscientific simulations and seismic processing to iterate models faster
- Financial Services: Conducting grid-computing simulations to identify portfolio risks and hedging opportunities
- Research: Processing complex workloads and analyzing massive data pipelines
This diversification demonstrates that HPC is now a business enabler across industries and is no longer limited to academia or specialized labs.
Apollo Tyres’ transformation was the session’s high point. Apollo Tyres faced a problem: fragmented on-premises infrastructure with no insight into global manufacturing efficiencies, while producing over 2,425 tons of tires every day across seven locations worldwide.
Their solution? Going all-in on AWS.
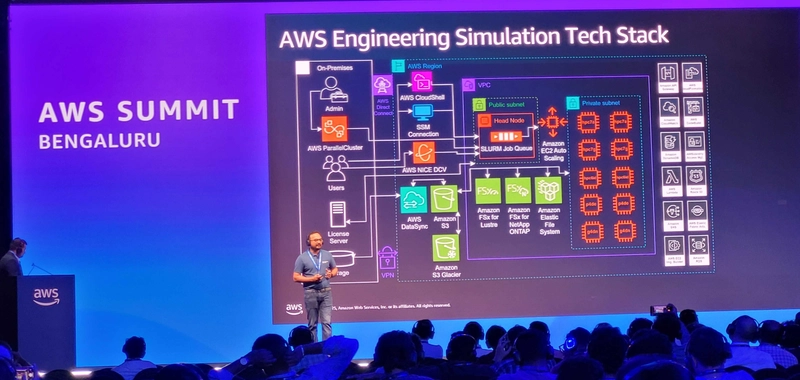
Their implementation of the architecture was remarkable. On-premises users access their cloud infrastructure over a VPN or AWS Direct Connect. HPC workloads are orchestrated by AWS ParallelCluster, while task queues are managed by SLURM. The storage layer makes use of FSx for Lustre, FSx for NetApp ONTAP, and Elastic File System, while the computing layer makes use of Amazon EC2 with auto-scaling. For remote engineers, AWS NICE DCV offers visualization capabilities.
The combination of several storage services, AWS DataSync and S3 for data transit, with S3 Glacier for archival is what makes this design especially beautiful. Apollo Tyres may save expenses for long-term storage while maintaining access to vital data thanks to this hybrid strategy.
The topic of machine learning for simulation, or ML4Sim, was perhaps the most futuristic. This method speeds up conventional HPC simulations using machine learning:
- Predict simulation results by learning relationships from historical simulation data
- Accelerate HPC simulations with embedded ML models that reduce computation time
- Learn solutions for governing equations directly, bypassing traditional numerical methods
- Create new designs with generative AI, enabling rapid prototyping
ML4Sim is an important change in the way engineering teams operate, especially in sectors like automotive and aerospace where each simulation might take hours or days.

The presenters demonstrated to us how each of these elements works together in a production setting. AWS ParallelCluster, which connects to the AWS Region via AWS CloudShell and SSM Connection, is used for on-premises administrator and user authentication. Public and private subnets are part of the VPC, and SLURM work queues are managed by a head node. Simulations are executed by compute nodes, and data passes across several FSx instances and S3 storage choices.
With services like EKS, OpenSearch, Cost Explorer, IAM, KMS, Secrets Manager, and CloudWatch, a thorough observability and governance layer, the Mumbai Region’s Tachyon Platform offers supervision on the management side.
Everything became realistic after witnessing Apollo Tyres’ real execution. Using DirectConnect or a VPN, users at Apollo’s on-premises locations access the cloud environment. They communicate using NICE DCV client desktops and web interfaces. NiceDCV workstations are used in the HPC configuration for visualization, and the AWS ParallelCluster (HPC Cluster) is connected to shared storage on FSx. LDAP/AD handles authentication, whereas the head node of the cluster controls the compute nodes that run simulations.
Apollo Tyres may preserve their current workflows while obtaining cloud scalability thanks to this architecture’s seamless on-premises and cloud integration.

The session concluded with three powerful benefits of HPC on AWS :
-
Virtually unlimited infrastructure enabling scaling and agility not attainable on-premises
-
Instant access to latest technologies with no lengthy procurement cycles or big capital investments
-
Flexible configuration options to optimize for both cost and performance
Apollo Tyres’ experience demonstrates that these are more than just marketing gimmicks. They have become an agile, data-driven company by moving mission-critical SAP apps to AWS and linking all of their factories to the cloud.
High-Performance Computing on AWS is revolutionizing businesses like Apollo Tyres through limitless scalability, immediate access to state-of-the-art technology, and adaptable cost minimization, according to the AWS Summit Bangalore 2025. From environment setup to ML4Sim, the seven-layer HPC tech stack offers a complete foundation for executing compute-intensive tasks in the cloud. HPC on AWS is more than simply a technical advancement; it’s a strategic business enabler that democratizes supercomputing for enterprises of all sizes, with a demonstrated return on investment (ROI) of $507 in revenue and $47 in profit for every dollar spent.
Regardless of your industry – automotive, pharmaceutical, genomics, or manufacturing, the question is not whether you should investigate HPC on AWS, but rather what innovative issues you will be able to resolve with it.
At the AWS Summit Bangalore 2025, this was just one of many exciting sessions. Stay tuned for one more insights from other session I attended!
Event: AWS Summit Bangalore 2025
Topic: HPC & Apollo Tyres Deep Dive
Date: May 08, 2025
Location: KTPO Exhibition Center in Whitefield, Bangalore

