Business and Technical Background
In today’s wave of digital transformation, enterprises are facing an explosive growth of massive data. Especially in critical scenarios such as data lake construction, BI analytics, and AI/ML data preparation, they require an efficient and scalable large-scale data storage solution.
These scenarios often demand storage systems that can handle PB- to EB-scale data while supporting transactional operations to ensure consistency, atomicity, and isolation—thus preventing data corruption or loss.
Against this backdrop, Apache Iceberg emerged as an advanced open-source data lake table format. It provides reliable metadata management, snapshot isolation, and schema evolution capabilities, and has been widely adopted by technology giants such as Netflix, Apple, and Adobe. Iceberg has now established itself as the leader in the data lake domain. According to industry reports, its adoption rate has been steadily increasing over the past few years, making it a de facto standard for building modern data infrastructure.
Despite Iceberg’s power, enterprises often encounter operational complexity, scalability challenges, and high maintenance overhead during deployment. This has created a strong demand for managed solutions to simplify operations.
At AWS re:Invent 2024, Amazon Web Services introduced S3 Tables, a feature that enhances the managed capabilities of Iceberg.
This innovation allows users to build and manage Iceberg tables directly on Amazon S3, eliminating the need for additional infrastructure investment. It significantly reduces operational cost and complexity, while leveraging the cloud’s global availability, durability, and scalability to boost elasticity and performance.
Such a fully managed, cloud-native approach is particularly suitable for high-availability and seamless integration scenarios, enabling enterprises to enjoy a true cloud-native data lake experience and ensuring stability under high-concurrency workloads.
In many business scenarios, data synchronization—especially CDC (Change Data Capture)—plays a vital role. It captures real-time changes from source databases and syncs them to target systems such as data lakes or warehouses.
- Real-time synchronization fits time-sensitive use cases such as fraud detection in financial platforms, real-time inventory updates in retail, or instant sharing of patient records in healthcare, ensuring that decisions are made on the freshest data.
- Offline (batch) synchronization is ideal for non-real-time scenarios such as daily backups, historical archiving, or scheduled report generation, efficiently processing large data volumes without unnecessary resource consumption.
Through these mechanisms, enterprises can efficiently achieve both CDC ingestion and batch synchronization, meeting diverse needs from real-time analytics to offline processing.
This article demonstrates how to use Apache SeaTunnel, a high-performance, distributed data integration tool, to integrate data into Amazon S3 Tables through Iceberg REST Catalog compatibility, enabling both real-time and batch data pipelines.
Architecture and Core Components

-
Integration via Iceberg REST Catalog in SeaTunnel
SeaTunnel natively supports Apache Iceberg REST Catalog, which provides a standardized interface for metadata read/write operations, simplifying client–catalog interaction.
Through this REST Catalog compatibility, SeaTunnel can directly and seamlessly register output table metadata into the Iceberg Catalog, without requiring custom plugin development or manual metadata synchronization—laying a solid foundation for automation and architectural decoupling in data lakes. -
Cloud-Native Data Lake Capability: S3 Tables + REST Endpoint
With the launch of S3 Tables, AWS now provides a built-in Iceberg REST Catalog Endpoint.
SeaTunnel can connect directly to S3 Tables—no modification required—to write batch or streaming data into Iceberg tables hosted on S3. Metadata and schema management are handled via the S3 Tables REST Endpoint.
This native integration greatly reduces the cost and complexity of cloud data lake adoption, enabling a serverless, cloud-native architecture where management and query layers are standardized, agile, and easily evolvable. -
Unified Data and Catalog Flow: Supporting CDC and Batch Synchronization
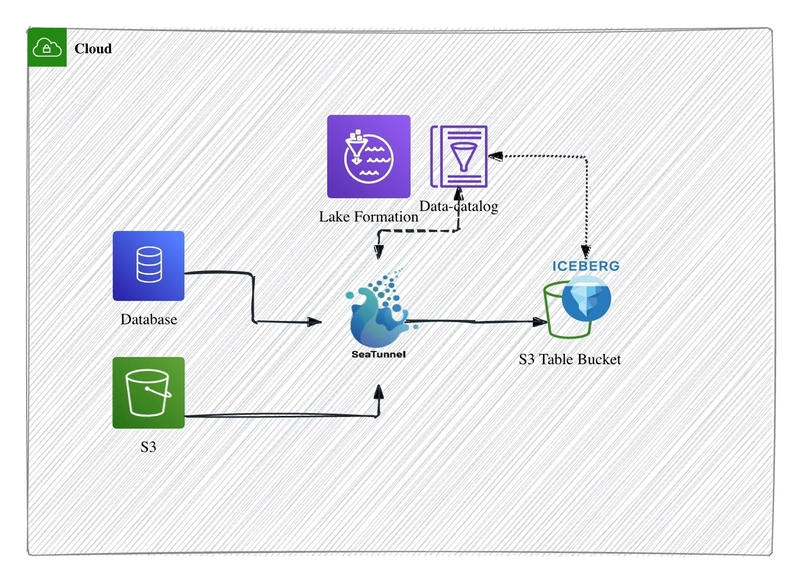
As shown in the diagram, SeaTunnel serves as the data integration hub. Whether ingesting from databases (OLTP/OLAP), S3 partitions, or streaming CDC data, all data first enters SeaTunnel.
Then, through SeaTunnel’s Iceberg Sink, data is written—either in real time or batch mode—into S3 Table Buckets. Meanwhile, Iceberg metadata is instantly registered in the Data Catalog service (e.g., Lake Formation) via the REST Catalog, ensuring one-stop coordination of business tables, metadata, and access control.
In CDC use cases, database changes are captured with low latency, maintaining data freshness. For batch ingestion or historical archiving, data is efficiently loaded into S3 Tables and managed under a unified Catalog, supporting hybrid data lakehouse queries.
In summary, the core innovation of this architecture lies in the standardization of data and metadata flow through the Iceberg REST Catalog, the cloud-native managed deployment enabled by AWS S3 Tables’ REST Endpoint, and SeaTunnel’s real-time + batch integration capabilities, delivering a one-stop, high-efficiency, and flexible data lake solution.
Data Integration Demo
1. Batch Data Integration
- Use SeaTunnel’s
FakeSourceto test batch writes into S3 Tables.
Edit the SeaTunnel configuration file with the Iceberg Sink configured for REST Catalog and AWS authentication:
env {
parallelism = 1
job.mode = "BATCH"
}
source {
FakeSource {
parallelism = 1
result_table_name = "fake"
row.num = 100
schema = {
fields {
id = "int"
name = "string"
age = "int"
email = "string"
}
}
}
}
sink {
Iceberg {
catalog_name = "s3_tables_catalog"
namespace = "s3_tables_catalog"
table = "user_data"
iceberg.catalog.config = {
type: "rest"
warehouse: "arn:aws:s3tables:::bucket/"
uri: "https://s3tables..amazonaws.com/iceberg"
rest.sigv4-enabled: "true"
rest.signing-name: "s3tables"
rest.signing-region: ""
}
}
}
- Run the SeaTunnel job locally:
./bin/seatunnel.sh --config batch.conf -m local
- Check the job logs:

- View the table in the S3 Tables bucket and query it using Athena:



2. Real-Time CDC Data Integration
- Use MySQL CDC source to test streaming data ingestion into S3 Tables.
Edit the SeaTunnel configuration file as follows:
env {
parallelism = 1
job.mode = "STREAMING"
checkpoint.interval = 5000
}
source {
MySQL-CDC {
parallelism = 1
result_table_name = "users"
server-id = 1234
hostname = "database-1.{your_RDS}.ap-east-1.rds.amazonaws.com"
port = 3306
username = ""
password = ""
database-names = ["test_st"]
table-names = ["test_st.users"]
base-url = "jdbc:mysql://database-1.{your_RDS}.ap-east-1.rds.amazonaws.com:3306/test_st"
startup.mode = "initial"
}
}
sink {
Iceberg {
catalog_name = "s3_tables_catalog"
namespace = "s3_tables_catalog"
table = "user_data"
iceberg.catalog.config = {
type: "rest"
warehouse: "arn:aws:s3tables:::bucket/"
uri: "https://s3tables..amazonaws.com/iceberg"
rest.sigv4-enabled: "true"
rest.signing-name: "s3tables"
rest.signing-region: ""
}
}
}
- Run the SeaTunnel job:
./bin/seatunnel.sh --config streaming.conf -m local
-
Observe the logs — CDC snapshot ingestion followed by change event streaming:

-
Verify the results in Athena:

Conclusion and Outlook
With the deep integration between Apache SeaTunnel, Apache Iceberg, and AWS S3 Tables, enterprise data lake architectures are entering a new era of flexibility and scalability.
In production environments, monitoring measures can be introduced by integrating Prometheus and Grafana for real-time metrics (including job status, throughput, and error logs), enabling proactive issue detection and rapid response.
Additionally, using Kubernetes or Docker Swarm for elastic deployment, enterprises can achieve auto-scaling and failover of SeaTunnel jobs, supporting dynamic resource allocation (e.g., load-based pod scaling).
This ensures the stability and high availability of ETL workflows while minimizing manual intervention and efficiently handling data surges.
Moreover, by leveraging AWS’s advanced services such as Athena for querying and Glue Crawler for automated schema discovery, organizations can further optimize Iceberg table performance.
For example, enabling S3 Intelligent-Tiering can lower storage costs, while integrating with Lake Formation strengthens data governance and access control.
These optimizations make data lakes more elastic and powerful for BI analytics and AI/ML data preparation—supporting low-latency queries on PB-scale datasets and efficient model training.
Note: Certain AWS generative AI-related services mentioned above are currently available in AWS’s overseas regions. AWS China (operated by Sinnet and NWCD) provides localized cloud services—please refer to the AWS China official site for details.