TL;DR
Plain RAG (vector + full-text) is great at fetching facts in passages, but it struggles with relationship answers (e.g., “How many times has this customer ordered?”). Context Mesh adds a lightweight knowledge graph inside Supabase—so semantic, lexical, and relational context get fused into one ranked result set (via RRF). It’s an opinionated pattern that lives mostly in SQL + Supabase RPCs. If hybrid search hasn’t closed the gap for you, add the graph.
The story
I’ve been somewhat obsessed with RAG and A.I. powered document retrieval for some time. When I first figured out how to set up a vector DB using no-code, I did. When I learned how to set up hybrid retrieval I did. When I taught my A.I. agents how to generate SQL queries, I added that too. Despite those being INCREDIBLY USEFUL when combined, for most business cases it was still missing…something.
Example:
Let’s say you have a pipeline into your RAG system that updates new order and logistics info (if not…you really should). Now let’s say your customer support rep wants to query order #889. What they’ll get back is likely all the information for that line-item; person who ordered, their contact info, product, shipping details, etc.
What you don’t get:
- total number of orders by that buyer,
- when they first became a customer,
- lifetime value,
- number of support interactions.
You can SQL-join your way there—but that’s brittle and time-consuming. A knowledge graph naturally keeps those relationships.
That’s why I’ve been building what I call the Context Mesh. On the journey I’ve created a lite version, which exists almost entirely in Supabase and requires only three files to implement (within Supabase, plus additional UI means of interacting with the system).
Those elements are:
- an ingestion path that standardizes content and writes to SQL + graph,
- a retrieval path that runs vector + FTS + graph and fuses results,
- a single SQL migration that creates tables, functions, and indexes.
Before vs. after
User asks: “Show me order #889 and customer context.”
Plain RAG (before):
{
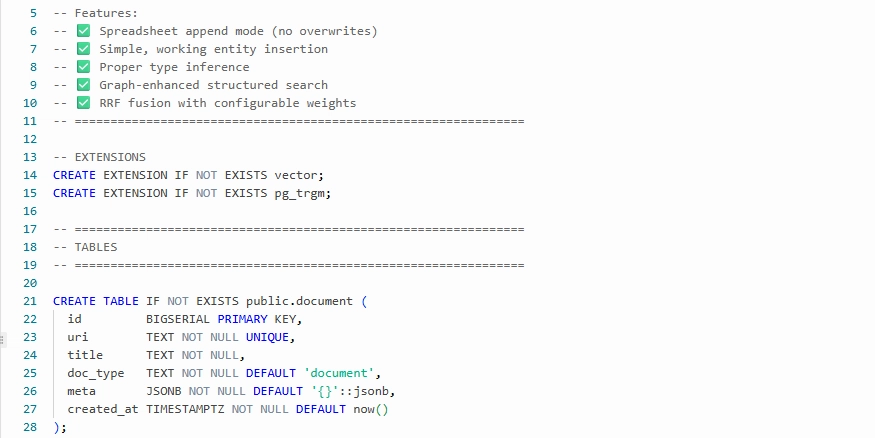
"order_id": 889,
"customer": "Alexis Chen",
"email": "alexis@example.com",
"items": ["Ethiopia Natural 2x"],
"ship_status": "Delivered 2024-03-11"
}
Context Mesh (after):
{
"order_id": 889,
"customer": "Alexis Chen",
"lifetime_orders": 7,
"first_order_date": "2022-08-19",
"lifetime_value_eur": 642.80,
"support_tickets": 3,
"last_ticket_disposition": "Carrier delay - resolved"
}
Why this happens: the system links node(customer: Alexis Chen) ⇄ orders ⇄ tickets and stores those edges. Retrieval calls search_vector, search_fulltext, and search_graph, then unifies with RRF so top answers include the relational context.
60-second mental model
[Files / CSVs] ──> [document] ──> [chunk] ─┬─> [chunk_embedding] (vector)
│
├─> [chunk.tsv] (FTS)
│
└─> [chunk_node] ─> [node] <─> [edge] (graph)
vector/full-text/graph ──> search_unified (RRF) ──> ranked, mixed results (chunks + rows)
What’s inside Context Mesh Lite (Supabase)
-
Documents & chunks with embeddings and FTS (
tsvector) -
Lightweight graph:
node,edge, pluschunk_nodementions - Structured registry for spreadsheet-to-SQL tables
- Search functions: vector, FTS, graph, and unified fusion
- Guarded SQL execution for safe read-only structured queries
The SQL migration (collapsed for readability)
1) Extensions
-- EXTENSIONS
CREATE EXTENSION IF NOT EXISTS vector;
CREATE EXTENSION IF NOT EXISTS pg_trgm;
Enables vector embeddings and trigram text similarity.
2) Core tables
CREATE TABLE IF NOT EXISTS public.document (...);
CREATE TABLE IF NOT EXISTS public.chunk (..., tsv TSVECTOR, ...);
CREATE TABLE IF NOT EXISTS public.chunk_embedding (
chunk_id BIGINT PRIMARY KEY REFERENCES public.chunk(id) ON DELETE CASCADE,
embedding VECTOR(1536) NOT NULL
);
CREATE TABLE IF NOT EXISTS public.node (...);
CREATE TABLE IF NOT EXISTS public.edge (... PRIMARY KEY (src, dst, type));
CREATE TABLE IF NOT EXISTS public.chunk_node (... PRIMARY KEY (chunk_id, node_id, rel));
CREATE TABLE IF NOT EXISTS public.structured_table (... schema_def JSONB, row_count INT ...);
Documents + chunks; embeddings; a minimal graph; and a registry for spreadsheet-derived tables.
3) Indexes for speed
CREATE INDEX IF NOT EXISTS chunk_tsv_gin ON public.chunk USING GIN (tsv);
CREATE INDEX IF NOT EXISTS emb_hnsw_cos ON public.chunk_embedding USING HNSW (embedding vector_cosine_ops);
CREATE INDEX IF NOT EXISTS edge_src_idx ON public.edge (src);
CREATE INDEX IF NOT EXISTS edge_dst_idx ON public.edge (dst);
CREATE INDEX IF NOT EXISTS node_labels_gin ON public.node USING GIN (labels);
CREATE INDEX IF NOT EXISTS node_props_gin ON public.node USING GIN (props);
FTS GIN + vector HNSW + graph helpers.
4) Triggers & helpers
CREATE OR REPLACE FUNCTION public.chunk_tsv_update() RETURNS trigger AS $$
BEGIN
SELECT d.title INTO doc_title FROM public.document d WHERE d.id = NEW.document_id;
NEW.tsv := setweight(to_tsvector('english', coalesce(doc_title,'')), 'A')
|| setweight(to_tsvector('english', coalesce(NEW.text,'')), 'B');
RETURN NEW;
END $$;
CREATE TRIGGER chunk_tsv_trg
BEFORE INSERT OR UPDATE OF text, document_id ON public.chunk
FOR EACH ROW EXECUTE FUNCTION public.chunk_tsv_update();
CREATE OR REPLACE FUNCTION public.sanitize_table_name(name TEXT) RETURNS TEXT AS $$
SELECT 'tbl_' || regexp_replace(lower(trim(name)), '[^a-z0-9_]', '_', 'g');
$$;
CREATE OR REPLACE FUNCTION public.infer_column_type(sample_values TEXT[]) RETURNS TEXT AS $$
-- counts booleans/numerics/dates and returns BOOLEAN/NUMERIC/DATE/TEXT
$$;
Keeps FTS up-to-date; normalizes spreadsheet table names; infers column types.
5) Ingest documents (chunks + embeddings + graph)
CREATE OR REPLACE FUNCTION public.ingest_document_chunk(
p_uri TEXT, p_title TEXT, p_doc_meta JSONB,
p_chunk JSONB, p_nodes JSONB, p_edges JSONB, p_mentions JSONB
) RETURNS JSONB AS $$
BEGIN
INSERT INTO public.document(uri, title, doc_type, meta) ... ON CONFLICT (uri) DO UPDATE ... RETURNING id INTO v_doc_id;
INSERT INTO public.chunk(document_id, ordinal, text) ... ON CONFLICT (document_id, ordinal) DO UPDATE ... RETURNING id INTO v_chunk_id;
IF (p_chunk ? 'embedding') THEN
INSERT INTO public.chunk_embedding(chunk_id, embedding) ... ON CONFLICT (chunk_id) DO UPDATE ...
END IF;
-- Upsert nodes/edges and link mentions chunk↔node
...
RETURN jsonb_build_object('ok', true, 'document_id', v_doc_id, 'chunk_id', v_chunk_id);
END $$;
6) Ingest spreadsheets → SQL tables
CREATE OR REPLACE FUNCTION public.ingest_spreadsheet(
p_uri TEXT, p_title TEXT, p_table_name TEXT,
p_rows JSONB, p_schema JSONB, p_nodes JSONB, p_edges JSONB
) RETURNS JSONB AS $$
BEGIN
INSERT INTO public.document(uri, title, doc_type, meta) ... 'spreadsheet' ...
v_safe_name := public.sanitize_table_name(p_table_name);
-- CREATE MODE: infer columns & types, then CREATE TABLE public.%I (...)
-- APPEND MODE: reuse existing columns and INSERT rows
-- Update structured_table(schema_def,row_count)
-- Optional: upsert nodes/edges from the data
RETURN jsonb_build_object('ok', true, 'table_name', v_safe_name, 'rows_inserted', v_row_count, ...);
END $$;
7) Search primitives (vector, FTS, graph)
CREATE OR REPLACE FUNCTION public.search_vector(p_embedding VECTOR(1536), p_limit INT)
RETURNS TABLE(chunk_id BIGINT, score FLOAT8, rank INT) LANGUAGE sql STABLE AS $$
SELECT ce.chunk_id,
1.0 / (1.0 + (ce.embedding <=> p_embedding)) AS score,
(row_number() OVER (ORDER BY ce.embedding <=> p_embedding))::int AS rank
FROM public.chunk_embedding ce LIMIT p_limit;
$$;
CREATE OR REPLACE FUNCTION public.search_fulltext(p_query TEXT, p_limit INT)
RETURNS TABLE(chunk_id BIGINT, score FLOAT8, rank INT) LANGUAGE sql STABLE AS $$
WITH query AS (SELECT websearch_to_tsquery('english', p_query) AS tsq)
SELECT c.id, ts_rank_cd(c.tsv, q.tsq)::float8, row_number() OVER (...)
FROM public.chunk c CROSS JOIN query q
WHERE c.tsv @@ q.tsq LIMIT p_limit;
$$;
CREATE OR REPLACE FUNCTION public.search_graph(p_keywords TEXT[], p_limit INT)
RETURNS TABLE(chunk_id BIGINT, score FLOAT8, rank INT) LANGUAGE sql STABLE AS $$
WITH RECURSIVE seeds AS (...), walk AS (...), hits AS (...)
SELECT chunk_id,
(1.0/(1.0+min_depth)::float8) * (1.0 + log(mention_count::float8)) AS score,
row_number() OVER (...) AS rank
FROM hits LIMIT p_limit;
$$;
8) Safe read-only SQL for structured data
CREATE OR REPLACE FUNCTION public.search_structured(p_query_sql TEXT, p_limit INT DEFAULT 20)
RETURNS TABLE(table_name TEXT, row_data JSONB, score FLOAT8, rank INT)
LANGUAGE plpgsql STABLE AS $$
BEGIN
-- Reject dangerous statements and trailing semicolons
IF p_query_sql IS NULL OR ... OR p_query_sql ~* '\b(insert|update|delete|drop|alter|grant|revoke|truncate)\b' THEN RETURN; END IF;
v_sql := format(
'WITH user_query AS (%s)
SELECT ''result'' AS table_name, to_jsonb(user_query.*) AS row_data, 1.0::float8 AS score,
(row_number() OVER ())::int AS rank FROM user_query LIMIT %s',
p_query_sql, p_limit
);
RETURN QUERY EXECUTE v_sql;
EXCEPTION WHEN ... THEN RETURN;
END $$;
9) Unified search with RRF fusion
CREATE OR REPLACE FUNCTION public.search_unified(
p_query_text TEXT, p_query_embedding VECTOR(1536),
p_keywords TEXT[], p_query_sql TEXT, p_limit INT DEFAULT 20, p_rrf_constant INT DEFAULT 60
) RETURNS TABLE(..., final_score FLOAT8, vector_rank INT, fts_rank INT, graph_rank INT, struct_rank INT)
LANGUAGE sql STABLE AS $$
WITH
vector_results AS (SELECT chunk_id, rank FROM public.search_vector(...)),
fts_results AS (SELECT chunk_id, rank FROM public.search_fulltext(...)),
graph_results AS (SELECT chunk_id, rank FROM public.search_graph(...)),
unstructured_fusion AS (
SELECT c.id AS chunk_id, d.uri, d.title, c.text AS content,
sum( COALESCE(1.0/(p_rrf_constant+vr.rank),0)*1.0
+COALESCE(1.0/(p_rrf_constant+fr.rank),0)*1.2
+COALESCE(1.0/(p_rrf_constant+gr.rank),0)*1.0) AS rrf_score,
MAX(vr.rank) AS vector_rank, MAX(fr.rank) AS fts_rank, MAX(gr.rank) AS graph_rank
FROM public.chunk c JOIN public.document d ON d.id=c.document_id
LEFT JOIN vector_results vr ON vr.chunk_id=c.id
LEFT JOIN fts_results fr ON fr.chunk_id=c.id
LEFT JOIN graph_results gr ON gr.chunk_id=c.id
WHERE vr.chunk_id IS NOT NULL OR fr.chunk_id IS NOT NULL OR gr.chunk_id IS NOT NULL
GROUP BY c.id, d.uri, d.title, c.text
),
structured_results AS (SELECT table_name, row_data, score, rank FROM public.search_structured(p_query_sql, p_limit)),
-- graph-aware boost for structured rows by matching entity names
structured_with_graph AS (...),
structured_ranked AS (...),
structured_normalized AS (...),
combined AS (
SELECT 'chunk' AS result_type, chunk_id, uri, title, content, NULL::jsonb AS structured_data, rrf_score AS final_score, ...
FROM unstructured_fusion
UNION ALL
SELECT 'structured', NULL::bigint, NULL, NULL, NULL, row_data, rrf_score, NULL::int, NULL::int, graph_rank, struct_rank
FROM structured_normalized
)
SELECT * FROM combined ORDER BY final_score DESC LIMIT p_limit;
$$;
10) Grants
GRANT USAGE ON SCHEMA public TO service_role, authenticated;
GRANT ALL ON ALL TABLES IN SCHEMA public TO service_role, authenticated;
GRANT ALL ON ALL SEQUENCES IN SCHEMA public TO service_role, authenticated;
GRANT EXECUTE ON ALL FUNCTIONS IN SCHEMA public TO authenticated, service_role;
Security & cost notes (the honest bits)
-
Guardrails:
search_structuredblocks DDL/DML—keep it that way. If you expose custom SQL, add allowlists and parse checks. - PII: if nodes contain emails/phones, consider hashing or using RLS policies keyed by tenant/account.
-
Cost drivers:
- embedding generation (per chunk),
- HNSW maintenance (inserts/updates),
- storage growth for
chunk,chunk_embedding, and the graph.
Track these; consider tiered retention (hot vs warm).
Limitations & edge cases
- Graph drift: entity IDs and names change—keep stable IDs, use alias nodes for renames.
-
Temporal truth: add
effective_from/toon edges if you need time-aware answers (“as of March 2024”). - Schema evolution: spreadsheet ingestion may need migrations (or shadow tables) when types change.
A tiny, honest benchmark (illustrative)
| Query type | Plain RAG | Context Mesh |
|---|---|---|
| Exact order lookup | ✅ | ✅ |
| Customer 360 roll-up | 😬 | ✅ |
| “First purchase when?” | 😬 | ✅ |
| “Top related tickets?” | 😬 | ✅ |
The win isn’t fancy math; it’s capturing relationships and letting retrieval use them.
Getting started
- Create a Supabase project; enable
vectorandpg_trgm. - Run the single SQL migration (tables, functions, indexes, grants).
- Wire up your ingestion path to call the document and spreadsheet RPCs.
- Wire up retrieval to call unified search with:
- natural-language text,
- an embedding (optional but recommended),
- a keyword set (for graph seeding),
- a safe, read-only SQL snippet (for structured lookups).
- Add lightweight logging so you can see fusion behavior and adjust weights.
(I built a couple of n8n workflows to easily interact with the Context Mesh; workflows for ingestion calling the ingest edge function, and a workflow chat UI that interacts with the search edge function.)
FAQ
Is this overkill for simple Q&A?
If your queries never need rollups, joins, or cross-entity context, plain hybrid RAG is fine.
Do I need a giant knowledge graph?
No. Start small: Customers, Orders, Tickets—then add edges as you see repeated questions.
What about multilingual content?
Set FTS configuration per language and keep embeddings in a multilingual model; the pattern stays the same.
Closing
After upserting the same documents into Context Mesh-enabled Supabase as well as a traditional vector store, I connected both to the chat agent. Context Mesh consistently outperforms regular RAG.
That’s because it has more access to structured data, temporal reasoning, relationship context, etc. All because of the additional context provided by nodes and edges from a knowledge graph. Hopefully this helps you down the path of superior retrieval as well.
Be well and build good systems.