
How Agentic Context Engineering (ACE) enables AI agents to improve through in-context learning instead of fine-tuning – a comprehensive implementation guide.

What is Agentic Context Engineering?
Agentic Context Engineering (ACE) is a machine learning framework introduced by researchers at Stanford University and SambaNova Systems in October 2025. The approach enables AI agents to improve performance by dynamically curating their own context through execution feedback, rather than relying on traditional fine-tuning methods.
Key Innovation: Instead of updating model weights through expensive fine-tuning cycles, ACE treats context as a living “playbook” that evolves based on what strategies actually work in practice.
Research Paper: Agentic Context Engineering (arXiv:2510.04618)

The Core Problem ACE Addresses
Modern AI agents face a fundamental limitation: they don’t learn from their execution history. When an agent makes a mistake, developers must manually intervene—editing system prompts, adjusting parameters, or fine-tuning the underlying model. This creates several challenges:
1. Repetitive Failures
Agents repeat the same mistakes across similar tasks because they lack institutional memory. Each task execution is independent, with no mechanism to apply lessons learned from previous attempts.
2. Manual Intervention Requirements
Developers spend significant time analyzing failure logs and manually updating prompts or configurations. This human-in-the-loop approach doesn’t scale as agent complexity increases.
3. Expensive Adaptation
Traditional fine-tuning requires:
- Labeled training datasets
- Computational resources for retraining
- Multiple iteration cycles ($10,000+ per cycle for production models)
- Weeks of development time
4. Black Box Improvement
Fine-tuning updates model weights in ways that are difficult to interpret, audit, or control. It’s unclear what the model “learned” or why performance changed.
How Agentic Context Engineering Works
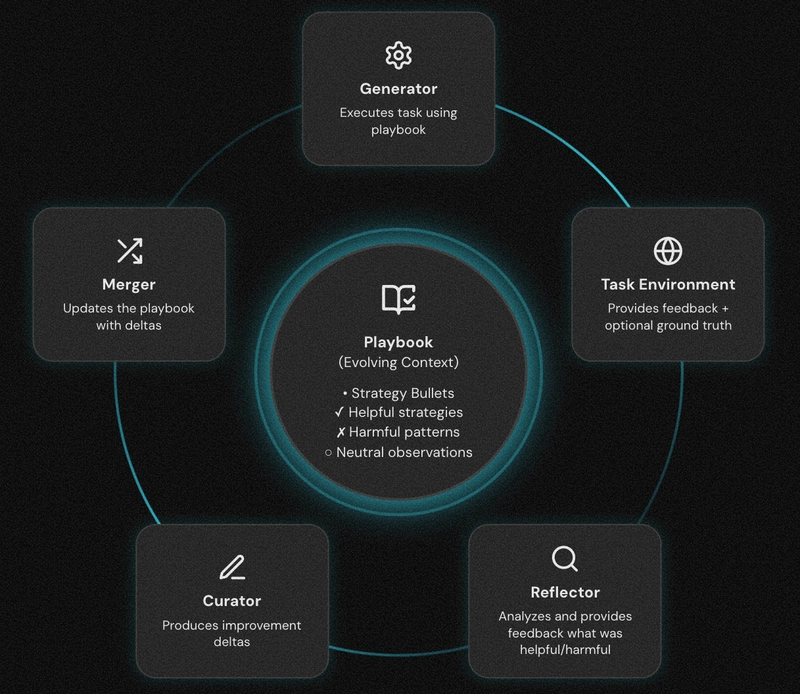
ACE introduces a three-agent architecture where specialized roles collaborate to build and maintain a dynamic knowledge base called the “playbook.”
The Three-Agent Architecture
1. Generator Agent
Role: Task Execution
The Generator performs the actual work—executing tasks using strategies retrieved from the current playbook. It operates like a traditional agent but with access to curated, task-relevant knowledge.
2. Reflector Agent
Role: Performance Analysis
The Reflector analyzes execution outcomes without human supervision. It examines:
- Task success or failure
- Execution patterns
- Output quality
- Error types
The Reflector identifies which strategies worked, which failed, and why—generating insights that inform playbook updates.
3. Curator Agent
Role: Knowledge Management
The Curator manages the playbook by:
- Adding new strategies based on successful executions
- Removing or marking strategies that consistently fail
- Merging semantically similar strategies to prevent redundancy
- Organizing knowledge by task type and context
The Playbook: Dynamic Context Repository
The playbook stores learned strategies as structured “bullets”—discrete pieces of knowledge with metadata:
{
"content": "When querying financial data, filter by date range first to reduce result set size",
"helpful_count": 12,
"harmful_count": 1,
"section": "task_guidance",
"created_at": "2025-10-15T10:30:00Z"
}
Each bullet includes:
- Content: The actual strategy or knowledge
- Helpful/Harmful counters: Feedback from execution outcomes
- Section: Category for organization (task guidance, error prevention, etc.)
- Metadata: Timestamps, source information, confidence scores
The Learning Cycle
- Execution: Generator receives a task and retrieves relevant playbook bullets
- Action: Generator executes using retrieved strategies
- Reflection: Reflector analyzes the execution outcome
- Curation: Curator updates the playbook with delta operations
- Iteration: Process repeats, with playbook growing more refined over time

Key Technical Components
Semantic Deduplication
As agents learn, they may generate semantically similar but lexically different strategies. ACE prevents playbook bloat through embedding-based deduplication. This ensures the playbook remains concise while capturing diverse knowledge.
Hybrid Retrieval Scoring
Instead of dumping the entire playbook into context, ACE uses hybrid retrieval to select only the most relevant bullets.
This approach:
- Keeps context windows manageable
- Prioritizes proven strategies
- Adapts to changing task patterns
- Reduces token costs
Delta Updates (Preventing Context Collapse)
A critical insight from the ACE paper: LLMs exhibit brevity bias when asked to rewrite context. They compress information, losing crucial details.
ACE solves this through delta updates—incremental modifications that never ask the LLM to regenerate entire contexts:
- Add: Insert new bullet to playbook
- Remove: Delete specific bullet by ID
- Modify: Update specific fields (helpful_count, content refinement)
This preserves the exact wording and structure of learned knowledge.
Performance Results from the Research
The Stanford team evaluated ACE across multiple benchmarks:
AppWorld Agent Benchmark
- +10.6 percentage points improvement in goal-completion accuracy vs. strong baselines (ICL, GEPA, DC, ReAct)
- +17.1 percentage points improvement vs. base LLM (≈40% relative improvement)
- Tested on complex multi-step agent tasks requiring tool use and reasoning
Finance Domain (FiNER)
- +8.6 percentage points improvement on financial reasoning tasks
- Demonstrated domain-specific knowledge accumulation
Adaptation Efficiency
- 86.9% lower adaptation latency compared to existing context-adaptation methods
- Significantly reduced rollout costs (fewer API calls, less compute)
Key Insight
Performance improvements compound over time. As the playbook grows, agents make fewer mistakes on similar tasks, creating a positive feedback loop.
Implementation: Building ACE in Practice
Architecture Considerations
Multi-Model Support
ACE works with any LLM that supports structured outputs:
- OpenAI (GPT)
- Anthropic (Claude)
- Google (Gemini)
- Local models (Llama 3, Mistral, Qwen)
Storage Layer
Playbooks can be stored in:
- SQLite (lightweight, local development)
- PostgreSQL (production, multi-user)
- Vector databases (optimized for semantic search)
Framework Integration
ACE integrates with existing agent frameworks:
- LangChain: Wrap existing agents with ACE
- LlamaIndex: Enhance RAG pipelines with learned strategies
- CrewAI: Multi-agent systems with shared playbooks
Current Limitations and Active Development
ACE is a powerful framework, but several challenges remain under active development:
1. Ambiguous Success Signals
For tasks with subjective quality metrics (creative writing, UI design), defining “success” is non-trivial. Current approaches:
- Use execution-based feedback when possible (tests pass/fail, API responses)
- Allow human-in-the-loop validation for ambiguous cases
- Research ongoing into self-assessment capabilities
2. Playbook Scale Management
As playbooks grow (1000+ bullets), challenges emerge:
- Retrieval quality may degrade without sophisticated ranking
- Semantic drift: old strategies may become outdated
- Solutions in development: hierarchical organization, automatic pruning, version control
3. Multi-Agent Coordination
When multiple agents share a playbook:
- Conflicts can arise from different learning patterns
- Merging strategies requires careful conflict resolution
- Research area: distributed playbook management
4. Evaluation Frameworks
Standardized benchmarks for ACE evaluation are still emerging. Current efforts focus on:
- Reproducible testing suites
- Domain-specific evaluation metrics
- Long-term learning curve measurements
Comparison: ACE vs. Other Approaches
ACE vs. Fine-Tuning
| Aspect | ACE | Fine-Tuning |
|---|---|---|
| Adaptation Speed | Immediate (after single execution) | Days to weeks |
| Cost | Inference only | $10K+ per iteration |
| Interpretability | Readable playbook | Black box weights |
| Reversibility | Edit/remove strategies easily | Requires retraining |
| Human Oversight | Audit playbook anytime | Post-hoc evaluation only |
ACE vs. RAG (Retrieval-Augmented Generation)
| Aspect | ACE | RAG |
|---|---|---|
| Knowledge Source | Learned from execution | Static documents |
| Update Mechanism | Autonomous curation | Manual document updates |
| Content Type | Strategies, patterns | Facts, references |
| Optimization | Self-improving | Requires query tuning |
ACE vs. Prompt Engineering
| Aspect | ACE | Prompt Engineering |
|---|---|---|
| Scalability | Automatic | Manual per use case |
| Maintenance | Self-updating | Constant tweaking |
| Coverage | Discovers edge cases | Predefined scenarios |
| Expertise Required | Minimal after setup | Deep prompt crafting |
Use Cases and Applications
Software Development Agents
- Code generation: Learn project-specific patterns (naming conventions, error handling)
- Bug fixing: Build knowledge of common errors and solutions
- Code review: Accumulate style guidelines and best practices
Customer Support Automation
- Ticket routing: Learn which issues need human escalation
- Response generation: Discover effective communication patterns
- Edge case handling: Build institutional knowledge of unusual requests
Data Analysis Agents
- Query optimization: Learn efficient data retrieval patterns
- Visualization selection: Discover which charts work for which data types
- Anomaly detection: Build baseline expectations from execution history
Research Assistants
- Literature search: Learn effective query strategies per domain
- Information synthesis: Discover citation patterns and summarization techniques
- Fact verification: Build knowledge of reliable sources
Community and Contributions
The ACE framework is under active development with a growing open-source community.
Contributing
Current Focus Areas
- Framework integrations (LangGraph, Vercel AI SDK, AutoGPT)
- Benchmark suite development
- Production optimization (caching, batching, async)
Research Collaborations
We welcome academic and industry collaborations. Contact us for:
- Evaluation on domain-specific benchmarks
- Integration with proprietary agent systems
- Research partnerships on ACE extensions
Conclusion
Agentic Context Engineering represents a paradigm shift in how AI agents improve over time. By treating context as a curated, evolving resource rather than a static prompt, ACE enables:
- Continuous learning from execution feedback
- Interpretable improvement through auditable playbooks
- Cost-effective adaptation without fine-tuning
- Scalable knowledge accumulation across tasks
While challenges remain—particularly around ambiguous success signals and playbook management at scale—the framework provides a practical path toward agents that genuinely learn from experience.
As the field evolves, ACE offers a foundation for building production-ready agents that improve autonomously, reducing the manual intervention that currently limits agent deployment.
Additional Resources
Research
Community
About the Author
Building production AI agents at Kayba AI. Implementing research in the real world. Always learning from execution feedback.
Keywords: Agentic Context Engineering, ACE framework, AI agents, self-learning agents, in-context learning, LLM agents, Stanford AI research, agent memory, autonomous learning, no fine-tuning, playbook-based learning, LangChain integration, production AI agents
Last Updated: October 2025

