
As a former teacher and curriculum developer, I’ve been curious about the potential of AI in scoring open-ended student responses. In this post, I’ll walk you through my prototype design of an AI scoring agent, explain the code, and explore its initial outputs. In a follow-up post, I’ll evaluate it’s performance using multiple inputs, and reflect on what we can learn from how the agent approaches scoring tasks.
All of the code and example outputs described in this article can be found in the GitHub repository.
The Prototype Design
When I started designing my scoring agent, I wanted it to be able to do the following:
- Score student responses to questions based on a provided scoring guide
- Provide a score and an explanation describing why it assigned the score
- Be able to look up facts on the web (if needed)
- Have some mechanism for quality control, by double-checking its work
After some exploration of multiple options, I decided to implement the AI Scoring Agent using the following tools:
- The prototype agent was built in the form of a Jupyter notebook for easy and lightweight experimentation
- LangChain was used to create the agent with Ollama chat and DuckDuckGo web search tool
- LangGraph was used to construct the Graph and direct the agent’s workflow
- NetworkX and Matplotlib were used to visualize the graph structure of the agent
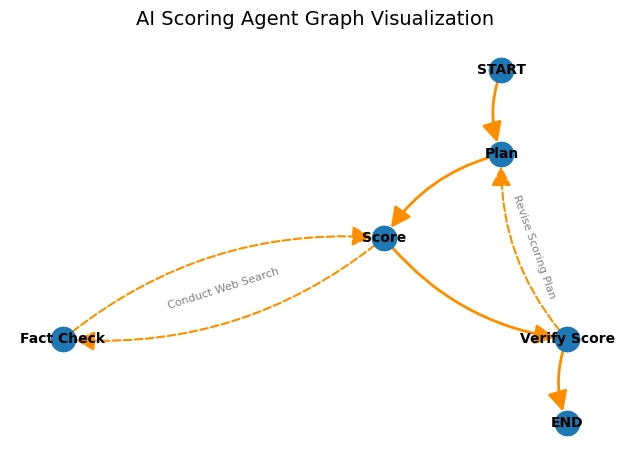
AI Agent Workflow: The Big Picture

The agent takes in three string inputs at the start: a question, a student response, and a scoring guide.
- In the planning node, it reads the question and the scoring guide, and creates a plan that it will follow to score a student response for that question.
- It then moves to the scoring node, and attempts to follow it’s plan to score the response.
- If it can score the response without any additional information, it scores it and moves to the verification node.
- If it needs to fact check anything, it can conduct a web search before scoring the response.
- After scoring, it passes the score and explanation to the verification node, where it checks it’s work.
- If the score is verified, the score and explanation are passed to the user as the final answer.
- If the score is not verified, the agent goes back to the planning node to make a new plan, rescore, and re-verify.
The Code
Follow along in the Jupyter notebook to explore the code and outputs discussed below.
Environment Setup, Installations, and Imports
I used a Jupyter notebook within a virtual environment in VSCode to work on this project. I installed all required packages in the virtual environment, including the following:
pip install langchain langchain-core langchain-community langgraph langchain-ollama networkx
The project requires the following imports:
# for creating the state and graph workflow
from langgraph.graph import StateGraph, END
# for integrating the LLM
from langchain_ollama import ChatOllama
# for integrating web search
from langchain_core.tools import tool
from langchain_community.tools import DuckDuckGoSearchRun
# for visualizing the graph
import networkx as nx
import matplotlib.pyplot as plt
# general tools
from typing import TypedDict, Optional
import json
import os
import re
Utility Functions
The next cell in the notebook organizes the utility functions that will be called. Look at the Jupyter notebook to see the code.
The first two are used to cache the agent’s plans so they can be re-used in future scoring tasks using the same question and scoring guide, which makes the agent more efficient and consistent across runs.
The extract_score_from_output function is used to pull a numeric score out of the agent’s output to be used for verification.
Building the Agent
The next cell includes all of the logic to build the agent, hook it up to the LLM, and give it tools, prompts, and a clear workflow. I’ll describe each chunk of code step-by-step.
Setting up the Agent and Tools
class AgentState(TypedDict):
question: str
student_response: str
scoring_guide: str
plan: str
score: Optional[int]
output: Optional[str]
retry_count: 0
fact_query: Optional[str]
fact_verified: Optional[str]
First, define the AgentState class. This is a typed dictionary that establishes the structure of the state that will be passed to each node as the agent performs its work. In this case, the question, student_response, and scoring_guide are required, and must be provided as input to the agent. The plan is required, and is generated in the planning node. The score and output are generated by the LLM in the scoring node, and are optional. In fact, the presence or absence of these keys is used to conditionally direct the agent to its next step. Similarly, the retry_count, fact_query, and fact_verified keys are also used to conditionally direct the agent. This will be explained as we build the nodes in the next section.
# Initialize the LLM using Ollama qwen2:7b
llm = ChatOllama(model="qwen2:7b")
This scoring agent is built upon an already-existing large language model, which allows it to interact with natural text prompts and compose its responses. I used an Ollama LLM because it was free, did not require an access key, and could be run locally.
# Set up web search tool for fact checking
@tool
def fact_check(query: str) -> str:
"""Search the web to verify science facts."""
search = DuckDuckGoSearchRun()
return search.run(query)
tools = [fact_check]
Autonomous agents generally have access to a number of different tools that they can optionally call as needed. In this case, the agent only has access to one tool, a web search tool. I chose the DuckDuckGo tool because it was also free and did not require any access keys.
Building the Nodes
In its current state, the scoring agent has 4 nodes:
A. Plan Node
B. Fact Check Node (Optional)
C. Score Node
D. Verify Score Node
Each node has a similar structure. Each node is set up as a function, which takes in the StateGraph as an argument, and can be called to execute the work of that node. Each node has the following components:
- a description of what it does (as well as and conditions)
- a textual prompt telling the LLM what to do
- a call to the LLM using the prompt, which generates a response
- logic on how to handle the response, including updating the StateGraph
The nodes themselves are fairly independent from one another. The logic for moving from one node to another in a workflow is generally defined in the graph structure, described in a later section.
A. Plan Node
The planing node is one of the simpler nodes: It checks if there is already a cached plan, and returns it. If there is not an existing plan, it sends a prompt to the LLM requesting it to generate a plan based on the scoring guide.
# Planning node
def plan_scoring_approach(state: AgentState):
"""
Checks if there is already a scoring plan in the cache.
If yes, reuses the existing plan.
If no, generates and caches a new plan.
"""
print("\n================== A. PLANNING SCORING APPROACH ==================")
cache = load_plan_cache()
# check if current question / scoring guide already in cache
key = f"{state['question']}|{state['scoring_guide']}"
if key in cache:
print("✅ Using cached plan")
plan = cache[key]
print(plan)
else:
print("🧠 Generating new plan")
prompt = (
"You are an expert scoring assistant who creates structured scoring plans for student responses.\n\n"
"Your goal is to analyze the question and scoring guide, summarize the key distinctions between scores, "
"and then write a clear, step-by-step flowchart plan for assigning a score.\n\n"
"### Instructions for this task:\n"
"1. Read the new question and scoring guide carefully.\n"
"2. Summarize the main distinctions between each score level.\n"
"3. Write a new flowchart plan, following the example format above (use bullet points and IF/THEN structure).\n\n"
f"### Question:\n{state['question']}\n\n"
f"### Scoring Guide:\n{state['scoring_guide']}\n\n"
"### Output Format:\n"
"**Summary:**
One of the key things to note in this function is the prompt itself. Note how you can use a formatted string (f"text {variable} text") to make sure the LLM is considering the correct resources from the state, such as {state['question'] and {state['scoring_guide']}. Markdown can be used to format, organize, and add emphasis to the prompt as well.
B. Fact Check Node (Optional)
The purpose of the fact checking node is to send a query to the LLM and receive web search results back. It can then attempt to score the student response using the additional information from the web search. This is optional, and the agent will decide if it is needed during each task.
# Fact checking node (as needed)
def fact_check_node(state: AgentState):
"""
Send a query to DuckDuckGo and receive web search results.
"""
print("\n================== B. FACT CHECKING (Optional) ==================")
query = state.get("fact_query", "")
if not query:
return {"output": "No query provided for fact-checking."}
result = fact_check.invoke({"query": query})
print(f"Fact check QUERY → RESULT: {query} → {result[:200]}...")
# Immediately rescore using verified info
prompt = (
"SYSTEM: You now have verified scientific information. "
"Use it to rescore the student response without calling any tools.\n\n"
f"FACTS:\n{result}\n\n"
f"PLAN:\n{state['plan']}\n\n"
f"STUDENT RESPONSE:\n{state['student_response']}\n\n"
"Your output must include:\n"
"SCORE:
C. Score Node
The scoring node is a bit more complex than the other nodes because it brings in more conditional logic. I experimented with multiple approaches in regards to HOW and WHERE to include conditional logic. For example, conditional logic could be written into the textual prompt in plain English, it could be written in code outside of the prompt using if...elif...else and comparison operators to define the conditions, or it could be handled in the graph structure itself, by creating additional smaller nodes to handle every condition and define routing across those nodes. There are pros and cons to each approach.
In its current state, this agent includes some code-based conditional logic, as it seemed more successful than text-based logic. This logic determines whether the agent will execute a web search to collect additional science facts to help score the response. This approach uses some of the optional keys in the state as flags to determine which action to take.
# Scoring node
def score_student_response(state: AgentState):
"""
Generate a score and explanation for the student response.
Optionally calls fact_check once; if fact is already verified, rescores only.
"""
print("\n================== C. SCORING STUDENT RESPONSE ==================")
# Build prompt
prompt = (
"SYSTEM: You are an assistant that scores student responses.\n"
"Follow the provided plan carefully.\n\n"
)
if state.get("fact_verified"): # already called fact check once
prompt += (
"SYSTEM: Verified factual information is already available.\n"
"Do NOT call any tool again.\n"
"Use ONLY the verified facts below when scoring.\n\n"
f"VERIFIED FACTS:\n{state['fact_verified']}\n\n"
)
else: # has not called fact check, may call fact check once
prompt += (
"If uncertain about a scientific fact, you MAY call the `fact_check` tool **once**.\n"
"Only verify objective facts relevant to the question.\n"
"Do NOT include student opinions or reasoning in your query.\n\n"
)
prompt += (
f"PLAN:\n{state['plan']}\n\n"
f"STUDENT RESPONSE:\n{state['student_response']}\n\n"
"Output format:\n"
"SCORE:
D. Verify Score Node
The final node is responsible for re-scoring the student response using the scoring guide, comparing the two scores it has generated for the response, and either verifying the score and returning it, or cycling back to create a new scoring plan and try again. The conditional logic within this node primarily focuses on limiting the re-planning and re-scoring to two total retries, in order to avoid getting stuck in an infinite loop without a clear score.
def verify_score_node(state: AgentState):
"""
Re-scores the student response and compares to old score.
If the scores do not match, reverts to plan node to make new plan and new score (up to 2 times).
"""
print("\n==================== D. VERIFYING SCORE ====================")
# If no score yet, generate it first at score node
if "score" not in state or state["score"] is None:
print("No score yet, generating one...")
score_result = score_student_response(state)
state.update(score_result)
# Prompt the model to independently score the student response based only on the guide
prompt = f"""
You are a scoring assistant. Ignore any previous scores or plans.
Your task:
1. Independently read the student response below.
2. Assign a new score strictly according to the SCORING GUIDE provided.
- Do NOT consider the previously assigned score in choosing the new score.
- Ensure the score does not exceed the maximum points described in the guide.
3. Return only a JSON object.
SCORING GUIDE:
{state['scoring_guide']}
STUDENT RESPONSE:
{state['student_response']}
Output:
Return ONLY a single JSON object with this format:
{{
"new_score": ,
"reason": ", "reason": "The student meets all criteria for this score."}}
"""
response = llm.invoke(prompt)
print(f"Verification response: {response.content}")
try:
verification_result = json.loads(response.content)
new_score = verification_result.get("new_score")
reason = verification_result.get("reason", "")
except Exception as e:
print("Failed to parse verification JSON:", e)
# If parsing fails, assume the score is verified to prevent infinite loops
print("\n******************** FINAL ANSWER *******************")
state["output"] += "\nCONFIDENCE: Low (Unverified Score)" # low confidence because verification failed
return {"output": state.get("output")}
# Compare the new score to the original
old_score = state.get("score")
print(f"OLD_SCORE: {state.get("score")} - NEW_SCORE: {new_score}")
try:
if int(new_score) == int(old_score):
verified = True
else:
verified = False
except:
verified = False
if verified:
# Accept score
print(f"\n******************** FINAL ANSWER *******************")
return {"output": state.get("output"), "verified": verified, "reason": reason}
elif state.get("retry_count", 0) >= 1:
# append confidence low
state["output"] += "\nCONFIDENCE: Low"
print(f"\n******************** FINAL ANSWER *******************")
return {"output": state.get("output"), "verified": verified, "reason": reason}
else:
# Increment retry count
state["retry_count"] = state.get("retry_count", 0) + 1
# Score not verified → clear plan and output to trigger a new plan
state["plan"] = None
state["output"] = None
# Delete the old plan from cache
cache = load_plan_cache()
key = f"{state['question']}|{state['scoring_guide']}"
if key in cache:
del cache[key]
save_plan_cache(cache)
return state
Building the Graph Structure
As noted above, the nodes are fairly independent of one another, and the workflow is instead directed by a graph structure with edges connecting the nodes. The code below shows how conditional logic is used to direct the workflow along certain edges, depending on the contents of the StateGraph.
# Build the graph
graph = StateGraph(AgentState)
# add nodes
graph.add_node("plan_node", plan_scoring_approach)
graph.add_node("score_node", score_student_response)
graph.add_node("verify_score_node", verify_score_node)
graph.add_node("fact_check_node", fact_check_node)
# set entry point
graph.set_entry_point("plan_node")
# add edges
graph.add_edge("plan_node", "score_node")
graph.add_edge("fact_check_node", "score_node")
graph.add_edge("verify_score_node", END)
# --- CONDITIONAL EDGES ---
# From SCORE node
def route_from_score(state: AgentState):
"""
Conditional routing after scoring:
- If a fact check is needed → go to fact_check_node
- If a score was produced → go to verify_score_node
- If facts were verified but output missing → go re-score
- Otherwise → end
"""
if state.get("fact_query"):
return "fact_check_node"
elif state.get("fact_verified") and not state.get("output"):
return "score_node" # re-score after facts retrieved
elif state.get("output"):
return "verify_score_node"
else:
return END
graph.add_conditional_edges(
"score_node",
route_from_score,
{
"fact_check_node": "fact_check_node",
"verify_score_node": "verify_score_node",
"score_node": "score_node", # needed for re-scoring after fact check
END: END,
}
)
# From VERIFY node
def route_from_verify(state: AgentState):
# If not verified and plan was cleared → regenerate plan (retry up to 2 times)
if state.get("plan") is None and state.get("retry_count", 0) <=1:
return "plan_node"
# If verified successfully → end
elif state.get("output"):
return END
# Otherwise → stop after 2 retries
else:
return END
graph.add_conditional_edges(
"verify_score_node",
route_from_verify,
{"plan_node": "plan_node", END: END}
)
# Compile the graph
app = graph.compile()
Visualizing the Graph
The next cell in the notebook includes code for visualizing the graph, and will not be discussed here.

As a recap: The question, student response, and scoring guide are passed to the planning node, which generates a scoring plan based on the scoring guide. In the scoring node, the response is scored, and the score and explanation are sent to the verification node to verify the score and return it as the final output.
If a web search is needed to collect factual information, the agent can conduct only one web search through the fact check node, and then return to score the response.
If the original score cannot be verified, then the against deletes the original scoring plan and returns to the planning node to create a new (and ideally better) plan. It then continues through the scoring and verification. There is a limit of only two retries, and the final answer is appended with a message that the confidence is low if the agent was unable to verify the score after the maximum allowed retries.
Initial Performance Demo
As you probably noticed in the code snippets, I included a lot of print statements to make the agent’s workflow and the LLM responses really transparent. Below, I will share one example of the model’s performance scoring a middle school science question. More analysis of the performance will be the subject of a second blog post, so stay tuned!
The Test Input
I used released science content from the 2023 Texas STAAR assessment for 8th grade science, which included multiple science questions, multiple student responses for each question at different score levels, and a scoring guide for each question. You can see the science content here.
scoring_guide_1 = "Score 2: The student response includes: There are a total of 7 atoms representing three elements in the formula AND The elements are sodium (2 atoms), sulfur (1 atom), and oxygen (4 atoms). Score 1: The student answers half of the question correctly.
Score 0: The response is incorrect or irrelevant."
question_1 = "Sodium sulfate (Na2SO4) is used to produce many products. Which elements are represented in the formula AND how many atoms of each element are represented in the formula?"
test_input_0 = {
"question": question_1,
"student_response": "13",
"scoring_guide": scoring_guide_1
}
result_0 = app.invoke(test_input_0)
print(result_0["output"])
The verbose output from this run is pasted below, and can be analyzed to see the agent run in its most simple form (A. Plan -> C. Score -> D. Verify). The agent determined that no fact checking was needed, so the web search tool was not used.
================== A. PLANNING SCORING APPROACH ==================
🧠 Generating new plan
**Summary:**
- **Score 2:** Includes correct identification of all elements (sodium, sulfur, oxygen) and their respective atoms in sodium sulfate formula.
- **Score 1:** Provides half-correct answer either missing one of the elements with their atom count or misidentifying an element.
- **Score 0:** Incorrect or irrelevant response.
**Flowchart Plan:**
- **Step 1:** Identify if the student answers both parts of the question correctly (elements and atoms).
- **IF** Student answers that there are sodium, sulfur, and oxygen elements AND
- **THEN** Check if student mentions correct atom counts for each element.
- **IF** Correct atom counts identified (2 sodium, 1 sulfur, 4 oxygen)
- **THEN** Assign Score 2
- **ELSE**
- **IF** Student identifies at least two elements correctly but not their corresponding atoms OR misses one element completely
- **THEN** Assign Score 1
- **ELSE**
- **IF** Answer contains no correct information about elements or atom counts, regardless of how many parts are addressed.
- **THEN** Assign Score 0
================== C. SCORING STUDENT RESPONSE ==================
Scoring Output: SCORE: 0
EXPLANATION: The response does not identify the elements or their atom counts in sodium sulfate.
==================== D. VERIFYING SCORE ====================
Verification response: {
"new_score": 0,
"reason": "The response does not include any information about atoms, elements, or the formula."
}
OLD_SCORE: 0 - NEW_SCORE: 0
******************** FINAL ANSWER *******************
SCORE: 0
EXPLANATION: The response does not identify the elements or their atom counts in sodium sulfate.
The output above shows that the agent created a scoring plan in the form of a structured flowchart, which it then used to score the student’s response of “13”, and give an explanation of why it assigned that score of 0 (“The response does not identify the elements or their atom counts in sodium sulfate.”). In the verification node, it re-scored the response a 0, and since it assigned the same score twice, it was verified and returned as the final answer.
While this run shows the promise of the scoring agent in generating correct scores and reasonable explanations that align with the scoring guide, there is much more to explore. Additional tests in the Jupyter notebook include varied paths that the agent can take in scoring, and the varied outputs it produces. The next blog post will evaluate its performance in multiple questions and student responses, and reflect on my lessons learned to apply to future prototypes.

