
Overview
The code implements a sophisticated RAG pipeline that:
- Processes a user’s natural language query to understand its intent and context.
- Retrieves relevant information from a knowledge base (vector database) using semantic search.
- Generates a coherent, accurate answer using a Large Language Model (LLM), grounded in the retrieved information.
- Returns the answer along with sources and metadata for transparency and traceability.
1. RAGConfig Dataclass
Function: A configuration container that holds all the tunable parameters and service endpoints for the RAG engine. Using a dataclass ensures a clean and organized configuration structure.
Features and Description:
- Service Endpoints: URLs for connecting to dependent microservices.
-
vector_db_url: Endpoint for the vector database service (e.g., Qdrant, Chroma) for semantic search. -
llm_service_url: Endpoint for the LLM inference service (e.g., vLLM, Text Generation Inference). -
data_warehouse_url&data_lake_url: Endpoints for other data sources (though not heavily used in the provided code).
-
- Search Configuration: Parameters controlling the retrieval process.
-
max_context_length: The maximum number of characters from retrieved documents to send to the LLM (to avoid exceeding model context windows). -
top_k_documents: The total number of document chunks to retrieve from the vector database. -
similarity_threshold: The minimum cosine similarity score a document must have to be considered relevant. -
context_overlap: (Unused in provided code) Typically used when chunking documents to prevent losing context at chunk boundaries.
-
- LLM Configuration: Parameters for the text generation step.
-
default_model: The name of the LLM model to use for generation (e.g., “llama2-7b-semiconductor”). -
max_tokens: The maximum number of tokens the LLM should generate in its response. -
temperature: Controls the randomness of the output (lower = more deterministic, higher = more creative).
-
- Query Processing: Flags to enable/disable advanced query manipulation.
-
enable_query_expansion: IfTrue, adds related semiconductor-specific terms to the query. -
enable_query_rewriting: IfTrue, rephrases questions into statements for better retrieval. -
enable_intent_classification: (Unused in provided code, but implied) Likely a flag for the overall intent classification step.
-
- Response Configuration: Parameters for the final output.
-
include_sources: Whether to include source documents in the response. -
max_sources: The maximum number of sources to return in the response. -
confidence_threshold: (Unused in provided code) Could be used to filter out low-confidence responses before returning them to the user.
-
2. QueryIntent Dataclass
Function: A structured data object to store the results of analyzing the user’s query. It captures the what and the about what of the query.
Features and Description:
-
intent_type: Categorizes the query’s purpose (e.g.,'analysis','troubleshooting','optimization','general'). This drives which data collections to search and how to prompt the LLM. -
confidence: A score (0.0 to 1.0) representing how confident the classifier is in the assignedintent_type. -
entities: A list of extracted named entities (e.g., “5nm”, “650°C”, “10 torr”) from the query. -
process_modules: A list of semiconductor process modules mentioned (e.g.,['lithography', 'etch']). -
equipment_types: A list of equipment types mentioned (e.g.,['scanner', 'etcher']).
3. SearchResult Dataclass
Function: A structured data object to represent a single document chunk retrieved from the vector database, along with its metadata and relevance score.
Features and Description:
-
content: The actual text content of the retrieved document chunk. -
source: The origin of the document (e.g., “AMAT Centura Manual”, “SEMI E10 Standard”). -
collection: The name of the vector database collection it was found in (e.g.,"equipment_manuals"). -
score: The similarity score (e.g., cosine similarity) between the query and this document. -
metadata: A dictionary of additional metadata from the vector DB (e.g.,doc_id,date,author). -
rank: The rank/position of this result within its specific collection.
4. RAGResponse Dataclass
Function: The final, comprehensive output of the RAG pipeline. It contains the answer and all supporting information, making the system transparent and auditable.
Features and Description:
-
answer: The final text generated by the LLM. -
sources: A list ofSearchResultobjects that were used as context for the generation. -
query_intent: TheQueryIntentobject derived from the user’s original query. -
context_used: The exact string of concatenated source content that was sent to the LLM. Crucial for debugging. -
confidence: An overall confidence score (0.0 to 1.0) for the response, calculated based on search scores, intent confidence, and response quality. -
response_time_ms: The total time taken to process the query, in milliseconds. Key for performance monitoring. -
tokens_generated: The number of tokens the LLM generated. -
model_used: The name of the LLM model that generated the answer.
5. QueryProcessor Class
Function: The NLP powerhouse of the RAG engine. It is responsible for understanding, enriching, and refining the user’s raw query to maximize the quality of retrieval.
Key Methods and Description:
-
_initialize_nlp(): Downloads NLTK data and loads the spaCy model for advanced NLP tasks like named entity recognition (NER). -
classify_intent(query: str) -> QueryIntent: The core intent classification method.- How it works: Uses regex patterns to match against the query text to identify keywords for
analysis,troubleshooting, andoptimization. - It scores each intent category and picks the one with the highest score.
- It calls entity and module extraction methods to populate the
QueryIntentobject.
- How it works: Uses regex patterns to match against the query text to identify keywords for
-
_extract_entities(query: str): Uses spaCy’s NER and custom regex patterns for semiconductor units (nm, °C, torr) to find specific values and terms in the query. -
_extract_process_modules(query: str)&_extract_equipment_types(query: str): Simple keyword matchers that check the query against predefined sets of domain-specific terms (lithography,scanner,etcher, etc.). -
expand_query(query: str, intent: QueryIntent) -> str: Query Expansion. Adds related terms to the query to broaden the search and improve recall. For example, a query about “lithography” might be expanded to include “exposure resist mask reticle overlay”. -
rewrite_query(query: str, intent: QueryIntent) -> str: Query Rewriting. Converts questions into statements, which are often better for semantic search. For example, “How to fix etcher error 123?” becomes “fix etcher error 123 procedure method steps troubleshooting”.
6. SemiconductorRAGEngine Class
Function: The main orchestrator. It ties all components together to execute the end-to-end RAG workflow.
Key Methods and Description:
-
__init__(config: RAGConfig): Initializes the engine with its configuration, creates aQueryProcessor, and sets up an asynchronous HTTP client. -
process_query(query: str, ...) -> RAGResponse: The primary public method. Its workflow is:- Intent Classification: Calls
query_processor.classify_intent(). - Query Enhancement: Expands and rewrites the query if enabled.
- Semantic Search: Calls
_semantic_search()with the processed query. - Context Building: Calls
_build_context()to format the retrieved results into a single string for the LLM. - Response Generation: Calls
_generate_response()to send the prompt (with context) to the LLM service. - Confidence Calculation: Calls
_calculate_confidence(). - Metrics & Logging: Records the processing time and logs metrics.
- Intent Classification: Calls
-
_semantic_search(query: str, ...) -> List[SearchResult]: Communicates with the vector database service. It uses theQueryIntentto_select_collections()(e.g., searchfailure_analysisfortroubleshootingintents) and performs a cross-collection search. -
_build_context(search_results: List[SearchResult], ...) -> str: Intelligently combines the top search results into a single string, ensuring it doesn’t exceed themax_context_length. It adds source attribution ([Source: ...]) and uses_diversify_results()to include results from different sources/collections, avoiding redundant information. -
_generate_response(original_query: str, context: str, ...) -> Dict[str, Any]: Constructs a detailed prompt for the LLM. It uses_build_system_prompt()to create an expert persona and task instructions tailored to the query intent. It then sends this prompt to the LLM service via HTTP and returns the result. -
get_health_status() -> Dict[str, Any]: A crucial method for deployment. It performs health checks on all dependent services (vector DB, LLM service) and reports their status, allowing for monitoring and alerting. -
shutdown(): Properly closes the HTTP client to avoid resource leaks during application shutdown.
7. Global Instance & Getter Function
-
_rag_engine = None: A global variable to hold a singleton instance of theSemiconductorRAGEngine. -
get_rag_engine(config: Optional[RAGConfig] = None) -> SemiconductorRAGEngine: A factory function that implements the Singleton pattern. It ensures only one instance of the RAG engine exists, which is efficient for resource management (e.g., HTTP connection pooling, loading models once). If no instance exists, it creates one; otherwise, it returns the existing one.

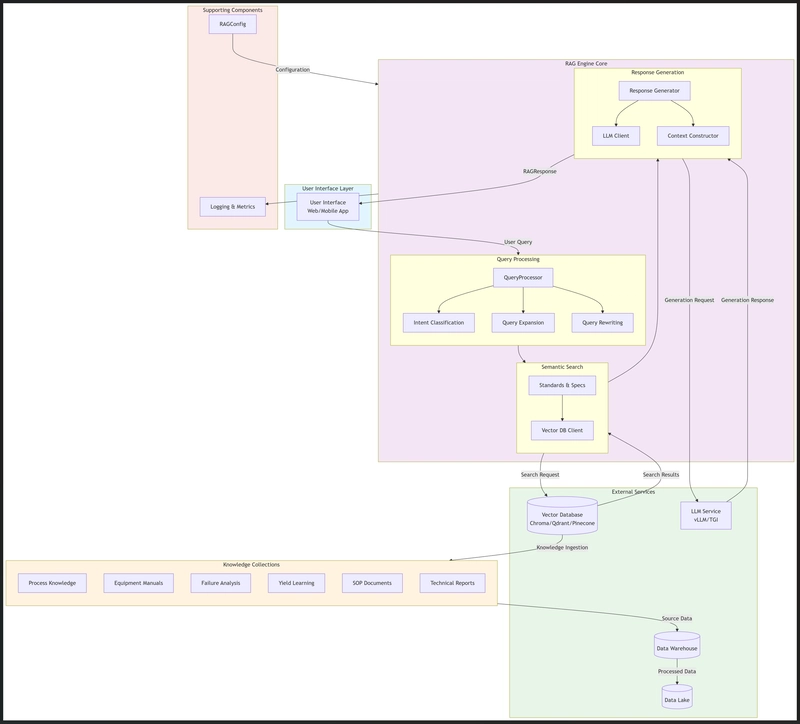
Information Flow Explanation
-
User Query Initiation:
- The process starts when a user submits a query through a User Interface (Web/Mobile App)
- The query is sent to the RAG Engine’s Query Processing module
-
Query Processing Phase:
- Intent Classification analyzes the query to determine its purpose (troubleshooting, optimization, analysis, or general)
- Query Expansion adds relevant semiconductor-specific terms to improve retrieval
- Query Rewriting reformulates questions into statements for better semantic search
-
Semantic Search Phase:
- The processed query is used to search the Vector Database
- Based on the determined intent, specific knowledge collections are targeted:
- Troubleshooting → Failure Analysis, Equipment Manuals, SOP Documents
- Optimization → Process Knowledge, Yield Learning
- Analysis → Technical Reports, Process Knowledge, Yield Learning
- Results are ranked by relevance and filtered by similarity threshold
-
Context Construction:
- The top search results are compiled into a context string
- Context is formatted with source attribution and trimmed to fit the LLM’s context window
- Diversification ensures information comes from multiple sources/collections
-
Response Generation:
- A specialized prompt is created combining system instructions, context, and the original query
- The prompt is sent to the LLM Service for generation
- The LLM returns a generated response grounded in the provided context
-
Response Delivery:
- The final response is packaged with sources, confidence score, and metadata
- The RAGResponse is returned to the User Interface
- Logs and metrics are recorded throughout the process
Key Architectural Features
- Modular Design: Each component has a specific responsibility, making the system maintainable and extensible
- Semantic Understanding: Goes beyond keyword matching to understand query intent and context
- Domain Specialization: Tailored specifically for semiconductor manufacturing with specialized knowledge collections
- Transparency: Provides sources and confidence scores to build trust in the AI’s responses
- Performance Monitoring: Built-in logging and metrics tracking for operational oversight
This architecture enables the RAG engine to provide accurate, context-aware responses to complex technical queries in the semiconductor manufacturing domain.
This document provides a detailed breakdown of the provided Python code, which implements a Retrieval-Augmented Generation (RAG) engine tailored for the semiconductor manufacturing AI ecosystem. The system combines semantic search, natural language processing (NLP), and Large Language Model (LLM) generation to deliver accurate, context-aware responses to technical queries.
📦 Overview of the System Architecture
The RAG engine operates in a modular pipeline:
- Query Processing: Enhance and classify user queries.
- Semantic Search: Retrieve relevant documents from a vector database.
- Context Building: Assemble and deduplicate retrieved information.
- Response Generation: Use an LLM with context to generate a response.
- Confidence Scoring & Response Packaging: Evaluate reliability and return structured output.
It uses:
-
HTTP clients (
httpx,aiohttp) to communicate with microservices. -
NLP libraries (
nltk,spacy,sentence-transformers) for query understanding. - Dataclasses for clean data modeling.
-
Asynchronous programming (
asyncio) for high performance.
🔧 Key Components and Their Functions
✅ 1. RAGConfig (Dataclass)
Purpose: Central configuration container for the RAG engine.
| Field | Type | Default Value | Description |
|---|---|---|---|
vector_db_url |
str |
"http://localhost:8091" |
Endpoint for the semantic search/vector DB service. |
llm_service_url |
str |
"http://localhost:8092" |
LLM inference API endpoint. |
data_warehouse_url |
str |
"http://localhost:8089" |
Not used directly; reserved for structured data integration. |
data_lake_url |
str |
"http://localhost:8090" |
Reserved for unstructured data access. |
max_context_length |
int |
4000 |
Max number of characters allowed in the context passed to the LLM. |
top_k_documents |
int |
10 |
Number of top documents to retrieve from search. |
similarity_threshold |
float |
0.7 |
Minimum similarity score for a document to be included. |
context_overlap |
int |
200 |
Unused in current code; likely intended for overlapping context chunks. |
default_model |
str |
"llama2-7b-semiconductor" |
Default LLM model name. |
max_tokens |
int |
1024 |
Max tokens to generate in the response. |
temperature |
float |
0.3 |
Controls randomness in LLM output (low = more deterministic). |
enable_query_expansion |
bool |
True |
Enables adding domain-specific terms to the query. |
enable_query_rewriting |
bool |
True |
Rewrites questions into statements for better retrieval. |
enable_intent_classification |
bool |
True |
Enables intent detection (analysis, troubleshooting, etc.). |
include_sources |
bool |
True |
Whether to include source attribution in the response. |
max_sources |
int |
5 |
Max number of sources to include in the final response. |
confidence_threshold |
float |
0.6 |
Minimum confidence to consider a response reliable. |
🛠️ Usage: This config is passed to the main engine and influences every stage of processing.
✅ 2. QueryIntent (Dataclass)
Purpose: Represents the classified intent and extracted entities from a user query.
| Field | Type | Description |
|---|---|---|
intent_type |
str |
One of: analysis, troubleshooting, optimization, general. Guides response strategy. |
confidence |
float |
Confidence score (0–1) of the intent classification. |
entities |
List[str] |
Extracted technical terms (e.g., “100nm”, “500°C”). |
process_modules |
List[str] |
Identified semiconductor processes (e.g., “lithography”, “etch”). |
equipment_types |
List[str] |
Equipment mentioned (e.g., “scanner”, “implanter”). |
🎯 Purpose: Enables context-aware retrieval and response generation by tailoring behavior to the query type.
✅ 3. SearchResult (Dataclass)
Purpose: Encapsulates a single document retrieved during semantic search.
| Field | Type | Description |
|---|---|---|
content |
str |
The actual text content of the document. |
source |
str |
Origin of the document (e.g., “manual_etcher_v2.pdf”). |
collection |
str |
Database collection (e.g., “equipment_manuals”). |
score |
float |
Similarity score from vector search (0–1). |
metadata |
Dict[str, Any] |
Additional metadata (e.g., author, date, process step). |
rank |
int |
Rank within its collection. |
🔍 Used to build the context and attribute sources in the final answer.
✅ 4. RAGResponse (Dataclass)
Purpose: Final structured response returned to the caller.
| Field | Type | Description |
|---|---|---|
answer |
str |
The generated natural language answer. |
sources |
List[SearchResult] |
Top sources used to generate the answer. |
query_intent |
QueryIntent |
Classified intent of the original query. |
context_used |
str |
Full context string sent to the LLM. |
confidence |
float |
Overall confidence in the answer (0–1). |
response_time_ms |
float |
Total processing time in milliseconds. |
tokens_generated |
int |
Number of tokens in the LLM output. |
model_used |
str |
Name of the LLM used. |
📦 This is the final output of the RAG pipeline — rich, traceable, and measurable.
🧠 QueryProcessor Class
Processes and enhances user queries before retrieval.
🔹 Initialization (__init__)
- Loads NLP models (
spaCy,NLTK). - Defines domain-specific vocabularies:
-
process_modules: Lithography, etch, deposition, etc. -
equipment_types: Scanner, etcher, furnace, etc. -
measurement_types: CD, overlay, thickness, etc.
-
- Downloads required NLTK datasets (
punkt,stopwords,averaged_perceptron_tagger). - Attempts to load
en_core_web_smspaCy model; falls back to regex if unavailable.
⚠️ Error Handling: Logs warnings if NLP models fail to load.
🔹 classify_intent(query: str) -> QueryIntent
Analyzes the query to determine user intent using regex-based pattern matching.
Intent Types:
| Intent | Trigger Keywords/Patterns |
|---|---|
| Analysis | “analyze”, “what causes”, “trend”, “correlation” |
| Troubleshooting | “fix”, “error”, “not working”, “root cause” |
| Optimization | “optimize”, “improve yield”, “adjust recipe” |
| General | Default fallback |
Logic:
- Scores each intent based on regex matches.
- Selects the highest-scoring intent.
- Calculates confidence as:
score / (total_score + 1). - Extracts entities and domain-specific terms.
- Returns a
QueryIntentobject.
✅ Used to route to appropriate knowledge bases and customize prompts.
🔹 _extract_entities(query: str)
Extracts technical measurements using regex patterns:
- Dimensions:
\d+nm,\d+um - Temperature:
\d+°C,\d+K - Pressure:
\d+torr,\d+mbar - Percentages:
\d+% - Angstroms:
\d+A
🧩 If spaCy is available, it uses NER; otherwise, falls back to regex.
🔹 _extract_process_modules(query: str)
Finds matches from the self.process_modules set (e.g., “litho”, “etch”).
🔎 Case-insensitive substring matching.
🔹 _extract_equipment_types(query: str)
Same logic as above, but for equipment (e.g., “scanner”, “furnace”).
🔹 expand_query(query: str, intent: QueryIntent)
Adds domain-specific synonyms based on detected process modules.
Example:
- Query:
"lithography issue" - Expanded:
"lithography issue exposure resist mask overlay"
📚 Enhances recall in semantic search by adding related terms.
🔹 rewrite_query(query: str, intent: QueryIntent)
Converts questions into statements for better semantic search matching.
Rewriting Rules:
| Input | Output |
|---|---|
What is lithography? → |
lithography definition explanation |
How to fix etcher error? → |
fix etcher error troubleshooting root cause solution |
Also appends intent-specific suffixes like:
-
" troubleshooting root cause solution"for troubleshooting queries.
🔁 Improves retrieval accuracy by aligning with how documents are phrased.
🤖 SemiconductorRAGEngine Class
Main orchestrator of the RAG pipeline.
🔹 Initialization (__init__)
- Accepts a
RAGConfig. - Initializes
QueryProcessor. - Sets up
httpx.AsyncClientfor async HTTP calls.
🔹 process_query(query: str, context: Optional[Dict]) -> RAGResponse
Core method: Executes the full RAG pipeline.
Steps:
-
Intent Classification:
query_processor.classify_intent() -
Query Enhancement:
- Expand query (if enabled)
- Rewrite query (if enabled)
-
Semantic Search:
_semantic_search() -
Context Building:
_build_context() -
LLM Generation:
_generate_response() -
Confidence Calculation:
_calculate_confidence() -
Response Packaging: Create
RAGResponse
⏱️ Measures and logs response time and metrics.
❌ On error, returns a safe fallback message.
🔹 _semantic_search(query: str, intent: QueryIntent)
Performs cross-collection vector search via HTTP.
Steps:
-
Select Collections based on intent using
_select_collections(). - Send POST request to
/search/cross-collectionwith:
{
"query": "processed query",
"collections": ["failure_analysis", "equipment_manuals"],
"top_k_per_collection": 5
}
- Parse results into
SearchResultobjects. - Filter by
similarity_threshold. - Return top
top_k_documents.
🔍 Uses intent to focus search scope and improve relevance.
🔹 _select_collections(intent: QueryIntent)
Maps intent to relevant document collections.
| Intent | Collections Added |
|---|---|
troubleshooting |
failure_analysis, equipment_manuals, sop_documents
|
optimization |
process_knowledge, yield_learning
|
analysis |
Adds process_knowledge, yield_learning
|
general |
All collections |
+ Process modules → process_knowledge
|
|
+ Equipment → equipment_manuals
|
🎯 Dynamic collection selection improves efficiency and relevance.
🔹 _build_context(search_results: List[SearchResult])
Assembles search results into a context string for the LLM.
Features:
- Limits total length to
max_context_length. - Adds source attribution:
[Source: manual.pdf | Collection: equipment_manuals]. - Uses
_diversify_results()to avoid redundancy. - Inserts
---separators between documents.
📑 Ensures traceability and avoids context overflow.
🔹 _diversify_results(results: List[SearchResult])
Prevents redundancy by ensuring diversity across:
- Sources (e.g., different PDFs)
- Collections (e.g., manuals vs. reports)
Algorithm:
- First pass: Pick top results from unique source+collection pairs.
- Second pass: Fill remaining slots with highest-scoring leftovers.
🔄 Avoids “echo chamber” effect where similar documents dominate.
🔹 _generate_response(original_query, context, intent)
Sends a prompt to the LLM service.
Prompt Structure:
[SYSTEM PROMPT]
Context Information:
[Source: X] ...
[Source: Y] ...
User Question: What causes CD variation in lithography?
Response:
System Prompt:
Built via _build_system_prompt(intent) — includes:
- Role definition: “Expert semiconductor engineer”
- Domain knowledge: SEMI standards, process modules, metrology
-
Intent-specific instructions:
- Troubleshooting → Root cause, steps, solutions
- Optimization → Trade-offs, recommendations
- Analysis → Trends, statistical significance
🧠 Tailored prompts lead to higher-quality, domain-appropriate answers.
🔹 _calculate_confidence(...) -> float
Estimates reliability of the response using weighted factors:
| Factor | Weight | Description |
|---|---|---|
| Avg. search score | 40% | Quality of retrieved documents |
| Intent confidence | 30% | How sure we are about the query type |
| Number of sources | 20% | More sources → higher confidence |
| Response length | 10% | Longer = more detailed (proxy) |
📊 Final score clamped to 0–1. Used for quality monitoring and routing decisions.
🔹 get_health_status() -> Dict
Checks availability of dependent services:
| Service | Check Endpoint | Healthy Status |
|---|---|---|
| Vector DB | /health |
HTTP 200 |
| LLM Service | /health |
HTTP 200 |
Returns:
{
"status": "healthy|degraded|error",
"services": {
"vector_db": "healthy",
"llm_service": "unreachable"
}
}
🩺 Used for monitoring and auto-recovery.
🔹 shutdown()
Safely closes the HTTP client to prevent resource leaks.
🧼 Ensures clean shutdown in async environments.
🌐 Global Instance & Factory Function
_rag_engine = None
def get_rag_engine(config: Optional[RAGConfig] = None) -> SemiconductorRAGEngine:
global _rag_engine
if _rag_engine is None:
if config is None:
config = RAGConfig()
_rag_engine = SemiconductorRAGEngine(config)
return _rag_engine
✅ Implements a singleton pattern to avoid recreating the engine.
💡 Ensures efficient resource usage in web servers or APIs.
📊 Logging and Metrics
-
logger: For operational logs (rag_manager). -
metrics_logger: For observability (counters, histograms).- Logs:
-
rag_queries_processed: Counter -
rag_response_time_ms: Histogram
📈 Enables performance monitoring, debugging, and SLA tracking.
✅ Summary of Key Features
| Feature | Description |
|---|---|
| Domain-Specific NLP | Understands semiconductor terms, units, and processes. |
| Intent-Aware Routing | Tailors search and response based on query type. |
| Query Expansion & Rewriting | Boosts retrieval recall and precision. |
| Multi-Source Context Building | Aggregates and deduplicates knowledge. |
| Confidence Scoring | Quantifies answer reliability. |
| Source Attribution | Transparent, auditable responses. |
| Async & Scalable | Uses asyncio and httpx for high throughput. |
| Health Monitoring | Checks service dependencies. |
| Configurable | All parameters are adjustable via RAGConfig. |
🚀 Use Case Example
User Query:
“Why is my etcher showing high particle counts after cleaning?”
Pipeline:
-
Intent:
troubleshooting(high confidence) - Entities: “particle counts”
- Process Module: “etch”
-
Query Rewritten:
"high particle counts after cleaning troubleshooting root cause solution" -
Search Collections:
failure_analysis,equipment_manuals,sop_documents - Retrieved Docs: SOP for post-cleaning verification, particle fault tree
- LLM Prompt: “Root cause analysis for high particle counts after etcher cleaning…”
- Response: Lists likely causes (residue, chamber contamination), steps to verify, and corrective actions.
- Sources: Cites SOP and failure analysis report.
- Confidence: 0.82
🛑 Potential Improvements
| Area | Suggestion |
|---|---|
| Query Expansion | Use embeddings to find semantically similar terms instead of hard-coded lists. |
| Entity Extraction | Fine-tune spaCy on semiconductor documents for better NER. |
| Caching | Cache frequent queries to reduce latency. |
| Fallback Mechanism | If confidence < threshold, escalate to human expert. |
| Feedback Loop | Allow users to rate responses to improve over time. |
✅ Conclusion
This RAG engine is a robust, domain-optimized AI assistant for semiconductor manufacturing. It combines semantic search, intent classification, context-aware prompting, and confidence estimation to deliver accurate, explainable, and trustworthy responses.
It is well-structured, modular, and production-ready, making it ideal for integration into:
- Factory support systems
- Engineer chatbots
- Yield enhancement platforms
- Knowledge management portals
📌 Final Note: This code exemplifies enterprise-grade RAG design — combining NLP, search, and LLMs in a reliable, observable, and maintainable way.

