
Docker is a very useful tool, not just for data engineers but for all developers alike. But before we get to it, let’s try to understand the concept it was built on
What is Containerisation?
- This is essentially packaging a piece of software alongside all its dependencies, including environment variables, and even an operating system, and running it as its own isolated instance, separate from your machine.
- It’s decoupling to the max, ensuring maximum portability for your application
Why containerise in data engineering
- Simplified Dependancy Management – A data workflow usually depends on various Python libraries, JVM versions, and certain tools’ versions. A container can encapsulate all this into a single image, eliminating the need to set up all these components manually.
- Scalability for Data pipelines – Containerisation allows data pipelines to be scaled up dynamically when used with tools like Kubernetes. This can be done individually for each stage of the data pipeline or for the whole thing
- Portability and easy integration with Cloud – Containers are running instances of a data pipeline completely decoupled from the machine running them, which means that they can run on any machine without that annoying, “It works on my machine”, phrase. This means that it can easily be deployed on any cloud environment as well
OK, so here’s a basic rundown of everything you need to know before we get our hands dirty.
- Docker is one of the software that’s used to perform containerisation.
- Docker Engine is the part of Docker that lives on your machine; it accesses your file system and applications and converts them into images. It also facilitates the running of these containers.
- Docker Hub is an online registry of container images. It’s where people can share the images they created for others to reuse, similar to GitHub
- Volumes are a way to ensure that the storage of a running container is persisted beyond the life span of the container. It’s like mapping a directory on your local machine to one on the container, such that changes made in that directory happen on both sides. Docker simply picks up where it left off when the container is restarted
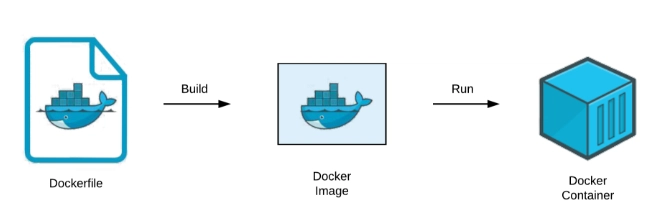
- A Docker File – is a simple text file we use to give docker instructions on how to build the image for the container.
- An Image is a snapshot of your application and its dependencies that can be called to create a Docker container, similar to an operating system image or a blueprint for a container
- Caches Docker images are built layer after layer; the changes between layers and the original/base layers are stored locally so that they can be reused again when rebuilding a container. This means that the initial build might take a long time, but subsequent builds are lightning fast.
- A Container is a running instance of the image. Docker uses an image to build and run a container.
Remember thats 
We only have to worry about creating the Docker file, then we build the image and run the container using Docker commands
To install Docker, you can follow this article on their official website, or you can follow this Digital Ocean article.
Running a Data Processing Script
To understand the rest of Docker, we’ll take a practical approach and learn as we go.
The goal is to create a simple data processing script that loads data into a pandas data frame, drops a column, and loads the result to a new, cleaned CSV.
We’ll also use docker volumes to persist the data
Create a home folder for Docker and then move into it
mkdir docker
cd docker
In here, you can clone a repository I made on GitHub for this purpose
git clone https://github.com/kazeric/docker_for_dataengineering
This should install a folder with the following files
app.py file contains the code for the app you want to containerise. I

cars.csv file the data to be transformed

Docker file contains the instructions for Docker to create the image

Here is a quick rundown of what it’s doing FROM python:3.10 – this pulls a base Docker image from Docker Hub. You can search “python:3.10 docker” and you’ll find it in Docker Hub. Anything after this line modifies the base image, the specifications we need to run our application
COPY requirements.txt . – this line copies the file requirements.txt to “.” which is the current working directory
RUN pip install -r requirements.txt – this line tells the container to run the pip command in the terminal
The rest are well explained by the comments
Note
The convention for Docker is that whenever there is a mapping, it’s usually local to the container, eg, in ports 5432:5432, in commands like COPY . ., in volumes ./data : opt/var/grafana/data
Now that we have it set up, let’s run the container
Build the image
docker build -t my_app .

Run the container
docker run my_app

Volumes
Now, let’s explore the new CSV created in Docker volumes
Find the specific container built from the image
docker ps -a
![]()
Get the container ID, use it to copy the container data to the host machine
docker cp :/app/data/cleaned_cars.csv ./data/cleaned_cars.csv
Your new CSV should look like this

Finally, clean up all the unused resources to free up space on your machine
docker system prune -a

-
Use small base images: Start from lightweight images like python:3.10-slim or alpine instead of full OS images to reduce build size and speed up deployment.
-
Clean up unused resources: Regularly remove unused containers, images, and networks with:
docker system prune -a
This keeps your environment tidy and reduces disk usage.
- Secure your containers: Avoid running containers as root. Use a non-root user and apply least-privilege principles. Keep your images updated to patch vulnerabilities.
Docker is a powerful tool that transforms how data engineers build, test, and deploy data pipelines — enabling consistent, reproducible environments across teams.
By containerizing ETL jobs, analytics tools, or machine learning models, teams save time and avoid “it works on my machine” issues.
For the next steps, you can check out Docker Compose, a simple yet powerful addition that makes running multi-container applications easy

