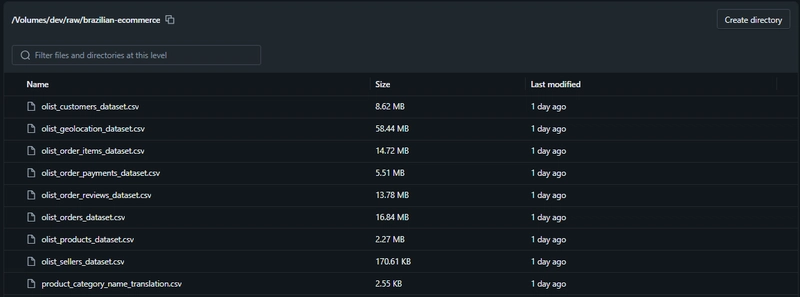
The goal of this project is to explore the Olist dataset about Brazilian e-commerce using Apache Spark.
Source: Brazilian E-commerce (Kaggle)
Engine: Spark
Environment: Databricks Notebook
1️⃣ Downloading the Dataset via API into Databricks Volumes
💡 Note: For Kaggle authentication, I generated the API token and used the Databricks CLI to set a secret with the token.
import os
import json
from kaggle.api.kaggle_api_extended import KaggleApi
kaggle_token = dbutils.secrets.get('kaggle', 'kaggle-token')
# expand home directory for the current user
kaggle_dir = os.path.expanduser('~/.config/kaggle')
os.makedirs(kaggle_dir, exist_ok=True)
kaggle_json_path = os.path.join(kaggle_dir, 'kaggle.json')
print(kaggle_json_path)
with open(kaggle_json_path, 'w') as f:
f.write(kaggle_token)
dataset_identifier = 'olistbr/brazilian-ecommerce'
volume_path = '/Volumes/dev/raw/brazilian-ecommerce'
api = KaggleApi()
api.authenticate()
api.dataset_download_files(dataset_identifier, path=volume_path, unzip=True)
📂 Each CSV file represents a different table:
2️⃣ Data Analysis
First, I set the base reader:
base_path = "/Volumes/dev/raw/brazilian-ecommerce"
What is the number of orders and the average payment value per status?
from pyspark.sql.functions import avg, sum, count, col
(
orders_payments.groupBy("order_status")
.agg(
count('*').alias("total_orders"),
avg(col("payment_value")).alias("avg_payment")
)
.orderBy("avg_payment", ascending=False)
.show()
)
# Output
+------------+------------+------------------+
|order_status|total_orders| avg_payment|
+------------+------------+------------------+
| processing| 319|217.53639498432602|
| canceled| 664|215.74638554216864|
| invoiced| 325|212.73227692307694|
| unavailable| 649|194.88368258859782|
| delivered| 100756|153.06742794473817|
| shipped| 1166| 151.9845283018868|
| created| 5| 137.62|
| approved| 2| 120.54|
+------------+------------+------------------+
What is the number of orders per state?
from pyspark.sql.functions import col, cast, count, sum
customers = (
spark.read
.options(header=True, inferSchema=True)
.csv(f"{base_path}/olist_customers_dataset.csv")
)
customers_payments = orders_payments.join(customers, on="customer_id", how="inner")
orders_by_state = (
customers_payments
.groupBy("customer_state")
.agg(
count('*').alias("order_count"),
sum(col("payment_value").cast("DECIMAL(10,2)")).alias("total_payments")
)
.orderBy("order_count", ascending=False)
)
orders_by_state.show()
# Output
+--------------+-----------+--------------+
|customer_state|order_count|total_payments|
+--------------+-----------+--------------+
| SP| 43622| 5998226.96|
| RJ| 13527| 2144379.69|
| MG| 12102| 1872257.26|
| RS| 5668| 890898.54|
| PR| 5262| 811156.38|
| SC| 3754| 623086.43|
| BA| 3610| 616645.82|
| DF| 2204| 355141.08|
| GO| 2112| 350092.31|
| ES| 2107| 325967.55|
| PE| 1728| 324850.44|
| CE| 1398| 279464.03|
| PA| 1011| 218295.85|
| MT| 958| 187029.29|
| MA| 767| 152523.02|
| MS| 736| 137534.84|
| PB| 570| 141545.72|
| PI| 524| 108523.97|
| RN| 522| 102718.13|
| AL| 427| 96962.06|
+--------------+-----------+--------------+
only showing top 20 rows
What is the average ticket per customer?
from pyspark.sql.functions import avg, col
(
customers_payments
.groupBy("customer_id")
.agg(
avg(col("payment_value").cast("DECIMAL(8,2)")).alias("avg_ticket")
)
.orderBy("avg_ticket")
.show()
)
# Output
+--------------------+----------+
| customer_id|avg_ticket|
+--------------------+----------+
|197a2a6a77da93f67...| 0.000000|
|3532ba38a3fd24225...| 0.000000|
|a73c1f73f5772cf80...| 0.000000|
|fd123d346a17cdf5e...| 1.737500|
|b246eeed30b362c09...| 1.856818|
|92cd3ec6e2d643d4e...| 2.410769|
|fc01c21e3a2b27c4d...| 3.166667|
|b6f7351952c806b73...| 3.776667|
|04bac030c03668923...| 3.870000|
|30a9fd4c676d1e0be...| 4.242500|
|eed931d3a5222a9a5...| 4.354211|
|a2afcfb0d0d309657...| 4.375000|
|7a0a62073458a64b4...| 4.464000|
|d3b38af3b96edca0f...| 4.698333|
|a790343ca6f3fee08...| 4.795000|
|e73a40f7509a5e81a...| 4.857143|
|c5ea6b40204131fb4...| 4.903333|
|e8b585de845954e2d...| 4.940000|
|c98632bdc4c3bd206...| 5.298333|
|7887f43daaa91055f...| 5.333333|
+--------------------+----------+
only showing top 20 rows
What is the average number of items per order?
order_items = spark.read.options(header=True).csv(f"{base_path}/olist_order_items_dataset.csv")
orders_order_items = orders.join(order_items, on="order_id")
items_per_order = (
orders_order_items
.groupBy("order_id")
.agg(count('order_item_id').alias('item_count'))
)
avg_items_per_order = items_per_order.agg(
avg("item_count").alias("avg_items_per_order")
)
display(avg_items_per_order)
display(items_per_order)
# Outputs
+-------------------+
|avg_items_per_order|
+-------------------+
| 1.1417306873695092|
+-------------------+
+--------------------+----------+
| order_id|item_count|
+--------------------+----------+
|ccbabeb0b02433bd0...| 1|
|c6bf92017bd40729c...| 1|
|ab87dc5a5f1856a10...| 1|
|06ff862a85c2402aa...| 1|
|f23155f5fa9b82663...| 1|
|69fd81b0cd556f5da...| 1|
|d40dd8018a5302969...| 1|
|42560dfc8d7863a19...| 2|
|3f003568147c78508...| 1|
|db192ddb0ea5a4d7a...| 1|
|5691d72069359cd29...| 1|
|8cae6053f4694ebc0...| 1|
|c1784064d438058cf...| 1|
|56cbdf3f7e3f53568...| 1|
|dfda6b8e30bc9ac25...| 3|
|322d561e43a3a0c58...| 2|
|d6a6d6c3e46448b61...| 1|
|387ca56ee49ac7729...| 1|
|c4de71df747f541f5...| 1|
|1004139d05100b9f2...| 1|
+--------------------+----------+
only showing top 20 rows
What are the top 10 cities with the most orders?
from pyspark.sql.functions import count, sum, col
orders = spark.read.option("header", True).csv(f'{base_path}/olist_orders_dataset.csv')
customers = spark.read.option("header", True).csv(f'{base_path}/olist_customers_dataset.csv')
payments = spark.read.option("header", True).csv(f'{base_path}/olist_order_payments_dataset.csv')
orders_customers_payments = (
orders
.join(payments, on="order_id")
.join(customers, on="customer_id")
)
(
orders_customers_payments.groupBy('customer_city')
.agg(count('order_id').alias('order_count'))
.orderBy('order_count', ascending=False)
.limit(10)
.show()
)
# Output
+--------------------+-----------+
| customer_city|order_count|
+--------------------+-----------+
| sao paulo| 16221|
| rio de janeiro| 7207|
| belo horizonte| 2872|
| brasilia| 2193|
| curitiba| 1576|
| campinas| 1515|
| porto alegre| 1418|
| salvador| 1347|
| guarulhos| 1250|
|sao bernardo do c...| 979|
+--------------------+-----------+
What are the top 10 cities with the highest total order value?
(
orders_customers_payments.groupBy('customer_city')
.agg(
sum(col('payment_value').cast("DECIMAL(10,2)")).alias('total_payments')
)
.orderBy('total_payments', ascending=False)
.limit(10)
.show()
)
# Output
+--------------+--------------+
| customer_city|total_payments|
+--------------+--------------+
| sao paulo| 2203373.09|
|rio de janeiro| 1161927.36|
|belo horizonte| 421765.12|
| brasilia| 354216.78|
| curitiba| 247392.48|
| porto alegre| 224731.42|
| salvador| 218071.50|
| campinas| 216248.43|
| guarulhos| 165121.99|
| niteroi| 139996.99|
+--------------+--------------+