
Introduction
Hey! In this article I’m going to share with you my process of how I created a research agent with ‘langflow’. This project is hosted on: sci-ai.streamlit.app
Outline
- Setting up Langflow and dotenv libraries:
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
from langchain.chat_models import init_chat_model
Langflow (which uses langchain underneath for some of the processing) is an agent orchestration library that is more organised and mature compared to just langchain.
Now, let’s import other necessary libraries as well:
from pydantic import BaseModel, Field
from typing_extensions import TypedDict
from typing import Annotated
from langchain_community.document_loaders import ArxivLoader
from semanticscholar import SemanticScholar
from langchain_community.utilities.semanticscholar import SemanticScholarAPIWrapper
import streamlit as st
import os
from io import BytesIO
import subprocess
import sys
# Load environment variables
load_dotenv()
We are using semanticscholar api and arxiv as credible sources for scientific research papers.For the sake of quick searching, we also use DDGS api [duckduckgo api]. Instead of writting the whole api request code from scratch, we make use of prebuilt tools provided by langchain for all of these. Why rebuild the wheel right?
api_key = st.secrets["GROQ_API_KEY"]
# Initialize LLM
llm = init_chat_model(
"groq:llama3-8b-8192",
api_key=api_key
)
if api_key:
print("Auth_key_found")
st.info("Auth_key_found")
Arxiv = []
ss = []
s = SemanticScholar()
sch = SemanticScholarAPIWrapper(
semanticscholar_search=s,
top_k_results=3,
load_max_docs=3
)
Here we initialise the semanticscholar class from the library, load the api key for groq api (llm inference) from the ‘secrets.toml’ file that you need to create in your file hierarchy.
The location of that file should be inside of a folder named ‘.streamlit’ (current_working_directory/.streamlit/secrets.toml)
File hierarchy:
current_working_directory
└── .streamlit
└── secrets.toml
sch = SemanticScholarAPIWrapper(
semanticscholar_search=s,
top_k_results=3,
load_max_docs=3
)
This is where we specify the number of papers we want to analyse. Remember that the more papers you decide to use, the more tokens the llm would need to process the data but the better the output is going to be. I found the sweet spot to be around 3-5 papers.
class State(TypedDict):
messages: Annotated[list, add_messages]
search_queries_arxiv: list[str]
search_queries_semanticscholar: list[str]
class Search_query(BaseModel):
queries_arxiv: list[str] = Field(..., description="list of queries for serching arxiv")
queries_semanticscholar: list[str] = Field(..., description="list of queries for serching semanticscholar")
# Build LangGraph
graph_builder = StateGraph(State)
Here we define a class named State that inherits the TypedDict class from the typing library. So whatever we define here is like a form the LLM can fill out(except for the ‘messeges’ one)! The messeges’ one is defined as an Nnotated list since we want to store the history here. In my usecase, I have defined 2 other fields for the LLM to fill based on the topic given by user, which are : ‘search_queries_arxiv’,’search_queries_semanticscholar’.
This is were the LLM generates the search queries to be searched about with the arxiv api and semanticscholar api.But remember that this is just definition we have not yet invoked the LLM to actually do the action of filling the fields. Think of this as just printing out a form you designed verses the filling out of the form by someone.
In order to generate a graph (let the llm full the fields we defined in state class), we feed the state class into the state-graph function of the langgraph library.
def query_construct(state: State):
structured_llm = llm.with_structured_output(Search_query)
last_message = state["messages"][-1]
user_message = last_message.content if hasattr(last_message, "content") else last_message["content"]
prompt = f"Based on this user request: '{user_message}', generate 2-3 specific search queries for finding relevant scientific papers."
search_query_obj = structured_llm.invoke(prompt)
if isinstance(search_query_obj, dict):
queries_arxiv = search_query_obj.get("queries_arxiv", [])
queries_semanticscholar = search_query_obj.get("queries_semanticscholar", [])
else:
queries_arxiv = getattr(search_query_obj, "queries_arxiv", [])
queries_semanticscholar = getattr(search_query_obj, "queries_semanticscholar", [])
return {"search_queries_arxiv": queries_arxiv, "search_queries_semanticscholar": queries_semanticscholar}
It is through this function that we actually ask the LLM to fill in the fields we defined earlier.
def source_aggregator(state: State):
queries = state.get("search_queries_arxiv", [])
queries_SS = state.get("search_queries_semanticscholar", [])
for q in queries:
try:
st.write(f"Searching Arxiv for: {q}")
loader = ArxivLoader(query=q, load_max_docs=1)
docs = loader.get_summaries_as_docs()
Arxiv.append(docs)
except Exception as e:
st.write(f"Error: {e}")
Arxiv.append(f"Error: {e}")
for qs in queries_SS:
st.write(f"Searching SemanticScholar for: {qs}")
r = sch.run(qs)
ss.append(r.get('abstract', '') if isinstance(r, dict) else None)
combined_info = f"Arxiv: {Arxiv}\nSemanticScholar: {ss}"
return {"messages": [{"role": "system", "content": combined_info}]}
This function is what searches for papers based on search terms on arxiv & semanticscholar APIs. First it accesses the search queries generated by the api via:
queries = state.get("search_queries_arxiv", [])
queries_SS = state.get("search_queries_semanticscholar", [])
Then we define a for loop that goes through each of the search query and searches them with the above mentioned APIs and appends them into their respective lists. This list is what containers the info to be processed by ‘parse_headings_and_body’ function.
def parse_headings_and_body(text):
paragraphs = []
for line in text.strip().split("\n"):
line = line.strip()
if line.startswith("**") and "**" in line:
heading = line[3:line.index("]**")]
paragraphs.append(("heading", heading))
elif line:
paragraphs.append(("body", line))
return paragraphs
This is a function we are defining to parse headings and body(split into paragraphs) of the paper, before feeding into the llm.
We do so by first declaring a variable named paragraphs holding a list. Then we define a for-loop which extracts paragraphs by looking for ‘**’ which is used to bolden given text by LLMs in their response for headings or subheadings. Then we append these into the list named paragraphs that we declared earlier. Then we return it.
def data_synthesis(state: State):
return {"messages": [llm.invoke(state["messages"])]}
This function just invokes the LLM to generate the report based on data given!
if st.button("Analyze") and usr_inp:
with st.spinner("Preparing your report..."):
# Build graph
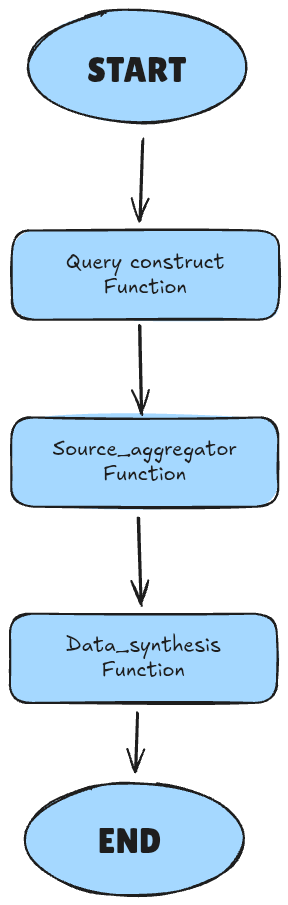
graph_builder.add_node("query_construct", query_construct)
graph_builder.add_node("source_aggregator", source_aggregator)
graph_builder.add_node("data_synthesis", data_synthesis)
graph_builder.add_edge(START, "query_construct")
graph_builder.add_edge("query_construct", "source_aggregator")
graph_builder.add_edge("source_aggregator", "data_synthesis")
graph_builder.add_edge("data_synthesis", END)
graph = graph_builder.compile()
state = graph.invoke({"messages": [{"role": "user", "content": usr_inp}], "search_queries": []})
parsed_resp = state['messages'][-1].content
st.write(parsed_resp)
text_file = BytesIO(parsed_resp.encode('utf-8'))
# Download button
st.download_button(
label="Download Report (txt)",
data=text_file,
file_name="Report.txt",
mime="text/plain",
icon="📄",
)
Here is where we do the ‘orchestration’ aspect of this project. Let’s see a basic diagram to better understand this:

And that’s it!

