How a simple unique value prevents duplicate payments, double orders, and customer frustration.
You’re finalizing a purchase online. You click “Pay Now.” The page hangs. The spinning wheel mocks you. Did it work? You have no idea. Your natural reaction is to hit the refresh button or click “Submit” again. But what happens next? Does the merchant charge your credit card twice?
In the world of distributed systems and unreliable networks, this scenario isn’t just a nuisance it’s a fundamental challenge. How can you ensure that a single, errant API request doesn’t accidentally create two orders, process two payments, or activate two devices?
The answer is elegant in its simplicity: the Idempotency Key. It’s a pattern that gives your APIs the superpower of safely handling retries, making your systems more resilient and reliable.
What Does “Idempotent” Even Mean?
In computer science, an operation is idempotent if performing it multiple times has the same effect as performing it once.
A classic example is a light switch. Flipping the switch up (ON) multiple times doesn’t change the outcome the light remains on. The “turn on” operation is idempotent. The “turn off” operation is also idempotent. However, pressing a “toggle” button is not idempotent; pressing it an even number of times leaves the light off, and an odd number of times leaves it on.
In API design, GET, PUT, and DELETE methods are typically designed to be idempotent. The problem child is POST, which is used for actions that create something new. By default, calling POST /charges twice creates two charges. An idempotency key changes this default behavior.
The Idempotency Key Pattern: A Client’s Secret Handshake
An idempotency key is a unique, client-generated value (like a UUID) that is sent with a request to an API endpoint. It’s the client’s way of saying: “This is the unique identifier for the operation I want to perform. If you’ve seen this key before, just give me the result of the previous operation instead of doing it again.”
Here’s the step-by-step flow that makes it work:
-
Client Creates a Key: Before making a non-idempotent request (e.g.,
POST /orders), the client generates a unique idempotency key, e.g.,idempotency-key: 4fa282fe-6f26-4f33-8a32-447c6d8a1953. -
First Request:
- The server receives the request and checks its fast data store (like Redis) for the key.
- The key is not found, so the server processes the request (creates the order, charges the card).
- The server stores the successful response (e.g., the order confirmation JSON) and the HTTP status code in its cache, associated with the idempotency key.
- The server returns the response to the client.
-
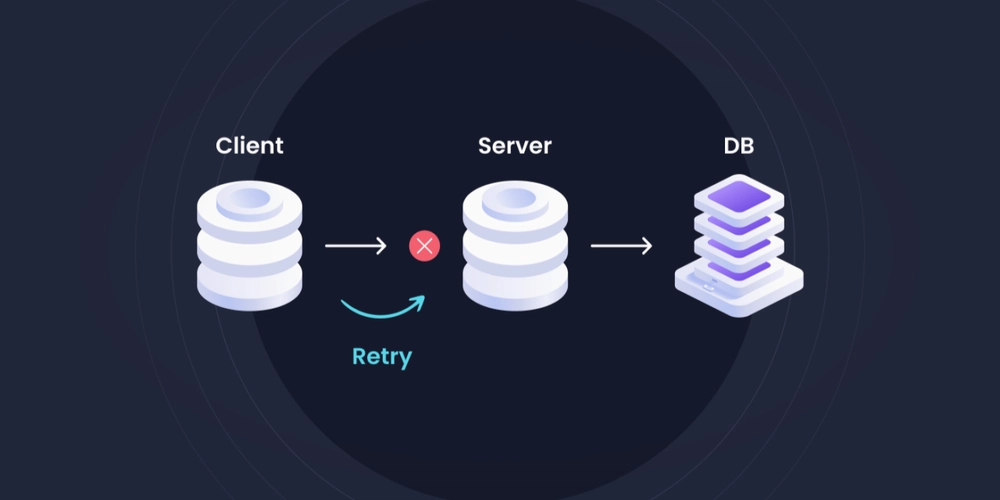
Client Retries (The Critical Part):
- The client never received the response (due to a network timeout, crash, etc.), so it retries the request with the exact same idempotency key and body.
- The server checks its cache and finds the key.
- Instead of executing the operation again, the server immediately returns the stored response from the first request.
- The operation (e.g., the payment) was only performed once, but the client can safely retry until it gets a definitive answer.
Why This Pattern is a Non-Negotiable Best Practice
- Resilience Against Network Uncertainty: Networks are inherently unreliable. Timeouts, dropped connections, and server hiccups are a fact of life. Idempotency keys allow clients to retry requests aggressively without fear of negative side effects.
- Prevents Duplicate Operations: This is the most obvious benefit. It eliminates duplicate payments, orders, account creations, or any other action that should only happen once.
- Simplifies Client Logic: The client doesn’t need complex logic to determine if a request should be retried. Its job is simple: retry until successful. The server handles the complexity of deduplication.
- Clear API Contracts: Offering idempotency for non-idempotent operations makes your API predictable and much easier for developers to integrate with. It’s a hallmark of a well-designed API.
Real-World Implementation: The Stripe Example
The Stripe API is a famous and excellent implementation of this pattern. To safely create a payment, you include an idempotency key in your request header.
curl https://api.stripe.com/v1/charges \
-u sk_test_123: \
-d amount=2000 \
-d currency=usd \
-d source=tok_amex \
-H "Idempotency-Key: 4fa282fe-6f26-4f33-8a32-447c6d8a1953"
If you need to retry this exact charge, you send the same exact command. Stripe’s servers will ensure your card is not charged again.
Key Considerations for Implementation
- Server-Side Storage: You need a fast, persistent storage layer (like Redis or DynamoDB) to store the key-response pairs. This store must be durable across server restarts.
- Time-to-Live (TTL): Don’t store these keys forever. Set a reasonable expiration (e.g., 24 hours) after which the key is deleted from the cache. The operation is unlikely to be retried after that point.
- Key Scoping: Often, the key is scoped to the API endpoint and the specific API key making the request. This means the same idempotency key can be used for different requests to different endpoints.
- Idempotency Key != Primary Key: The idempotency key is for preventing duplicate execution. The resource you create (e.g., an order) will have its own unique ID in your system.
The Bottom Line
Building APIs without idempotency keys for state-changing operations is like building a car without seatbelts. You might be a perfect driver, but you need protection against the unexpected actions of others and the unpredictability of the road.
Implementing idempotency keys is a relatively simple technical investment that pays massive dividends in reliability, user trust, and developer experience. It transforms your API from a fragile chain of requests into a resilient, robust, and trustworthy system. In the modern digital economy, that trust is your most valuable currency.
Next in Security and Compliance: Now that we understand how to make single operations safe, how do we ensure a group of operations behaves predictably? This brings us to one of the oldest and most important concepts in database reliability: ACID and BASE Compliance.