
Before learning about threads and their details, please check the article about Python Concurrency: Processes, Threads, and Coroutines Explained.
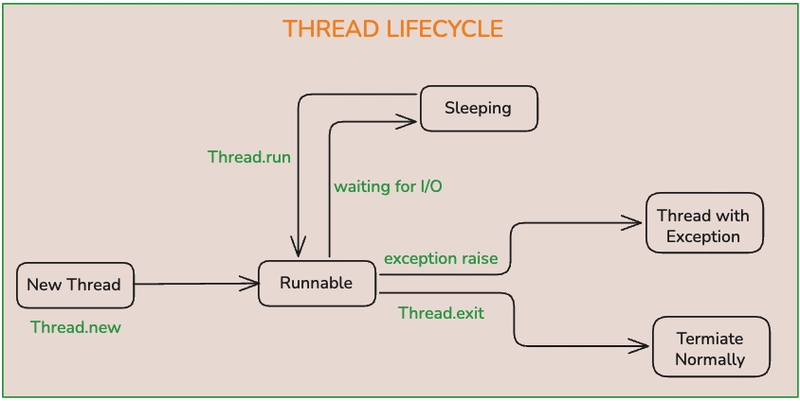
Thread Lifecycle
Every thread in Python goes through specific states:

New (Created)
A Thread object is created but not yet started. The OS has not scheduled it.
import threading
def worker():
print("Thread is working...")
t = threading.Thread(target=worker)
print("Thread created but not started yet.")
# Output: Thread created but not started yet.
Runnable
After calling .start(), the thread is ready to run. It is in a queue waiting for CPU scheduling. It does not run immediately; the OS decides when to give CPU time.
t.start() # Thread is now RUNNABLE
Running
When the OS scheduler gives CPU time, the thread starts executing. Only one Python thread executes at a time (because of the GIL).
Terminated (Dead)
The thread finishes execution or is stopped. Once finished, it cannot be restarted.
t.join() # Waits until the thread is TERMINATED
Context Switching
OS can switch between threads anytime. This creates the illusion of parallelism (concurrency). In CPython, only one thread runs at a time due to the GIL. So, context switching happens between Python threads frequently.
Scheduling
It is controlled by the OS and Python runtime. It cannot be predicted which thread runs first.
Join
The join() function makes the main thread wait until a thread finishes. Without join, the main thread may finish before the child threads.
Daemon Threads
They run in the background and are automatically killed when the main program exits. They are ideal for background services (logging, monitoring).
- Use
daemon=Trueto create daemon threads.
Example:
import threading, time
def background():
while True:
print("Daemon running...")
time.sleep(1)
t = threading.Thread(target=background, daemon=True)
t.start()
time.sleep(3)
print("Main thread exiting; daemon killed automatically")
Output:
Daemon running...
Daemon running...
Daemon running...
Main thread exiting; daemon killed automatically
Note:
- The daemon nature of the running thread cannot be changed.
- The default daemon nature of the main thread is False (Main thread is non-daemon, which can be changed).
- Any new thread gets its daemon nature from its parent thread.
Important Functions
-
.daemon: to check/update the nature of the daemon. -
setDaemon(): to update the nature of the daemon.
Synchronisation Primitives
In multithreading, threads often need to share data (like variables, files, lists, or database connections). The risk is that multiple threads might try to modify the same resource at the same time. For example, two threads adding money to the same bank account; if they both read the old balance before either writes, the final result will be wrong.
When multiple threads try to access or modify the same shared resource (like a global variable, file, or database), it creates race conditions.
A race condition happens when the final result depends on the unpredictable timing of threads — for example, two threads incrementing a counter at the same time might both read the same old value before writing, leading to lost updates.
To prevent this, the threading module provides synchronisation primitives, which are special objects that coordinate thread access to shared resources.
Locks (Mutual Exclusion)
It ensures only one thread executes a critical section. Without a lock, there will be race conditions.
Example:
import threading
counter = 0
lock = threading.Lock()
def increment():
global counter
for _ in range(100000):
with lock: # prevents race condition
counter += 1
# Creating 5 threads and starting them
threads = [threading.Thread(target=increment) for _ in range(5)]
[t.start() for t in threads]
[t.join() for t in threads]
print("Final counter:", counter)
# Output: Final counter: 500000
Note:
- The line (
lock = threading.Lock()) creates a mutex lock (mutual exclusion object).- The with block (
with lock: counter += 1) means acquire the lock before entering this block, and automatically release it when leaving the block.
Important Functions
-
lock_object.acquire([blocking=True], timeout=-1)- It attempts to acquire the lock.
- By default, it blocks until the lock is available.
- Can set
blocking=Falseto attempt a non-blocking acquire, and timeout specifies how long to wait.
-
lock_object.release()- Releases the lock so that other threads can acquire it.
- Must be called after
acquire().
RLocks (Reentrant Locks)
Using RLocks, a single thread can acquire the lock multiple times (it keeps a counter internally). The thread must release it the same number of times before another thread can use it. RLock is used when the same thread might need to acquire the lock multiple times, such as in recursive functions or nested method calls using the same lock. Without it, a normal Lock would cause a deadlock. It also has acquire() and release() functions.
Example:
import threading
"""
lock = threading.Lock()
Do not use the simple mutex lock because the same thread will try to get the lock, and the program hangs.
"""
lock = threading.RLock()
def recursive(n):
with lock: # First acquire
print("Acquired lock at n =", n)
if n > 0:
recursive(n-1)
recursive(3)
Output:
Acquired lock at n = 3
Acquired lock at n = 2
Acquired lock at n = 1
Acquired lock at n = 0
Note:
- Lock can be acquired once and released once, but RLock can be acquired multiple times.
- RLock contains the details of the current thread, but Lock does not contain such information.
Scenario where RLock is needed
Suppose there is a class where multiple methods are synchronised with the same lock. One method calls another method that also uses the lock.
import threading
class Account:
def __init__(self, balance):
self.balance = balance
self.lock = threading.RLock() # Use RLock here
def withdraw(self, amount):
with self.lock: # First lock
if self.balance >= amount:
self.balance -= amount
print(f"Withdrew {amount}, balance = {self.balance}")
self.log_transaction(amount)
def log_transaction(self, amount):
with self.lock: # Second lock (nested)
print(f"Transaction logged: -{amount}")
- If the normal
Lockis used, this would deadlock becausewithdraw()acquires the lock, then callslog_transaction(), which tries to acquire the same lock again. - With an
RLock, the same thread can re-acquire safely.
Semaphores
A semaphore can be treated as a counter that limits the number of threads that can access a resource simultaneously. Unlike a lock (which allows only one thread at a time), a semaphore allows up to N threads. It also has acquire() (which increments the internal counter) and release() (which decrements the internal counter) functions.
Example:
import threading, time
sem = threading.Semaphore(2) # max 2 threads at a time
def task(n):
with sem:
print(f"Thread {n} entered")
time.sleep(1)
print(f"Thread {n} exited.")
for i in range(5):
threading.Thread(target=task, args=(i,)).start()
Output:
Thread 0 entered
Thread 1 entered
Thread 0 exited.
Thread 1 exited.
Thread 2 entered
Thread 3 entered
Thread 3 exited.
Thread 2 exited.
Thread 4 entered
Thread 4 exited.
Note:
- If no value is specified in the Semaphore object (for example,
obj = Semaphore()), then it behaves like a lock.- Python also provides
BoundedSemaphore, which is similar to Semaphore but adds a safety check, i.e., if a thread callsrelease()more times thanacquire(), it will raise aValueError.This helps catch programming errors where the semaphore is accidentally released too many times.
Thread Communication
Events
An event is like a flag (like a signal light) that one thread sets, and other threads can wait for. A thread can wait() on the event; it will pause until another thread sets the flag with set().
It is useful when one thread must wait for a signal before continuing (like waiting for data to load or a task to complete).
Example:
import threading
import time
event = threading.Event()
def waiter():
print("Thread is waiting for event...")
event.wait() # blocks until event.set() is called
print("Thread got the event! Continuing work...")
t = threading.Thread(target=waiter)
t.start()
time.sleep(2) # simulate some work
print("Main thread sending signal...")
event.set() # signal the waiting thread
Output:
Thread is waiting for event...
Main thread sending signal...
Thread got the event! Continuing work...
Important Functions
-
set(): Sets the internal flag toTrue. All threads waiting on the event will be unblocked. -
clear(): Resets the flag toFalse. Threads callingwait()after this will block untilset()is called again. -
is_set(): ReturnsTrueif the event flag is currently set, elseFalse. Useful for checking the state without blocking. -
wait(timeout=None): Blocks until the event flag is set. If the flag is alreadyTrue, the thread continues immediately. If a timeout is given, it waits at most that many seconds.-
Syntax:
event.wait(timeout)
-
Syntax:
Conditions
A condition is a variable that is used when threads need to wait until something happens. For example, a consumer waits for an item, and the producer notifies them once the item is available. Without this, the consumer might try to get from the queue when it is empty. It also has acquire() and release() functions.
Example:
import threading
condition = threading.Condition()
queue = []
def consumer():
with condition:
while not queue:
condition.wait() # wait for producer
item = queue.pop(0)
print("Consumed:", item)
def producer(item):
with condition:
queue.append(item)
print("Produced:", item)
condition.notify() # wake up consumer
threading.Thread(target=consumer).start()
threading.Thread(target=producer, args=(42,)).start()
# Output:
# Produced: 42
# Consumed: 42
Important Functions
-
wait(timeout=0): Suspends the calling thread until it is notified or until an optional timeout occurs. Typically used when a thread is waiting for a specific condition to become true.-
Syntax:
condition.wait(timeout)
-
Syntax:
-
acquire(): Acquires the underlying lock associated with the condition. This must be done before calling wait(), notify(), or notify_all().-
Syntax:
condition.acquire()
-
Syntax:
-
release(): Releases the lock previously acquired. This allows other threads to obtain the lock and proceed.-
Syntax:
condition.release()
-
Syntax:
-
notify(): Wakes up one of the threads waiting on the condition (if any). It should be called only when the thread has the lock.-
Syntax:
condition.notify()
-
Syntax:
-
notify_all(): Wakes up all threads currently waiting on the condition. Useful when multiple waiting threads need to be signalled at once.-
Syntax:
condition.notify_all()
-
Syntax:
-
enter()andexit(): These allow a Condition to be used as a context manager with the with statement. This automatically handles acquiring and releasing the lock, making the code cleaner and less error-prone.
Timer Object
It is a special type of thread that allows scheduling a function to run after a certain delay. It is useful in case there is a need to defer execution of a task, such as triggering an alert, retrying a request, or executing periodic jobs. Once started, the timer will wait for the specified interval in the background and then call the assigned function.
Example:
import threading
def greet(name):
print(f"Hello, {name}! This was delayed.")
# Create a timer that waits 3 seconds before running `greet`
timer = threading.Timer(3.0, greet, args=("Sushant",))
print("Timer started... waiting for execution")
timer.start()
# Uncomment to cancel before execution
# timer.cancel()
Output:
Timer started... waiting for execution
Hello, Sushant! This was delayed.
Important Functions
-
threading.Timer(interval, function, args=None, kwargs=None): Creates a timer that will callfunctionafterintervalseconds. -
.start(): Starts the timer. -
.cancel(): Cancels the timer (only before it has executed).
Barriers
A Barrier makes threads wait for each other. If Barrier(3) is used, then it means 3 threads must reach the barrier point before they can all continue. Once all threads reach the barrier, they are released together.
Example:
barrier = threading.Barrier(3)
def worker(n):
print(f"Thread {n} reached barrier")
barrier.wait()
print(f"Thread {n} passed barrier")
for i in range(3):
threading.Thread(target=worker, args=(i,)).start()
Output: (the order can be different)
Thread 0 reached barrier
Thread 1 reached barrier
Thread 2 reached barrier
Thread 2 passed barrier
Thread 1 passed barrier
Thread 0 passed barrier
Important Functions
-
.wait(): Makes a thread wait until the required number of threads have reached the barrier. -
.reset(): Resets the barrier to its initial state, useful if the barrier is broken. -
.abort(): Forces the barrier into a broken state, releasing all waiting threads with aBrokenBarrierError. -
.parties: Returns the number of threads that must callwait()before they are all released. -
.n_waiting: Returns the number of threads currently waiting at the barrier. -
.broken: ReturnsTrueif the barrier is in a broken state.
Thread-Local Storage
Each thread has its own copy of data. Each thread prints its own value, which does not create any conflicts.
Example:
local = threading.local()
def worker(val):
local.value = val
print(f"Thread {val}: {local.value}")
for i in range(3):
threading.Thread(target=worker, args=(i,)).start()
Output:
Thread 0: 0
Thread 1: 1
Thread 2: 2
Thread Pools vs Manual Threading
Manual Threading
Manual threading means creating and managing threads manually (by yourself).
It involves:
- Starting threads
- Joining them
- Handling exceptions
- Deciding how many threads to spawn
It gives full control over how threads are created and run, allowing developers to fine-tune priority, scheduling, and even custom stopping logic. But it becomes hard to manage when there are dozens or hundreds of tasks. The risk of creating too many threads leads to memory overhead, context switching issues.
For example, if the use case is to download 1000 files. If manual threading is used, there is a need to start 1000 threads (bad idea).
Code:
import threading
import time
def download_file(file_id):
print(f"Downloading file {file_id}...")
time.sleep(1) # simulate download
print(f"Finished file {file_id}")
threads = []
# Suppose we want to download 10 files
for i in range(10):
t = threading.Thread(target=download_file, args=(i,))
threads.append(t)
t.start()
# Wait for all threads to finish
for t in threads:
t.join()
Thread Pools (ThreadPoolExecutor)
Instead of creating threads manually, use a pool (a fixed number of worker threads). Just submit tasks, and the pool decides which thread executes them.
It is much simpler as there is no need to manage the thread lifecycle. Threads are reused, avoiding the overhead of constant creation/destruction. It is also safer as it prevents too many thread issues.
For example, instead of making 1000 threads to download files, make a pool of 10 workers. Each worker thread takes a download job one by one until all 1000 are finished. In this way, only 10 threads exist, but 1000 downloads still happen.
Code:
from concurrent.futures import ThreadPoolExecutor
import time
def download_file(file_id):
print(f"Downloading file {file_id}...")
time.sleep(1) # simulate download
print(f"Finished file {file_id}")
# A pool of 3 threads handles all tasks
with ThreadPoolExecutor(max_workers=3) as executor:
executor.map(download_file, range(10))
Stay tuned for the next article, where I will dive into practice problems, code examples, and common interview questions on multithreading in Python.

