
1. Hashing: The Core Concept
Hashing is a technique used to convert a large key into a small integer value that serves as an index in an array. This array is called a Hash Table. The primary goal is to achieve near-O(1) (constant time) complexity for insertion, deletion, and retrieval operations.
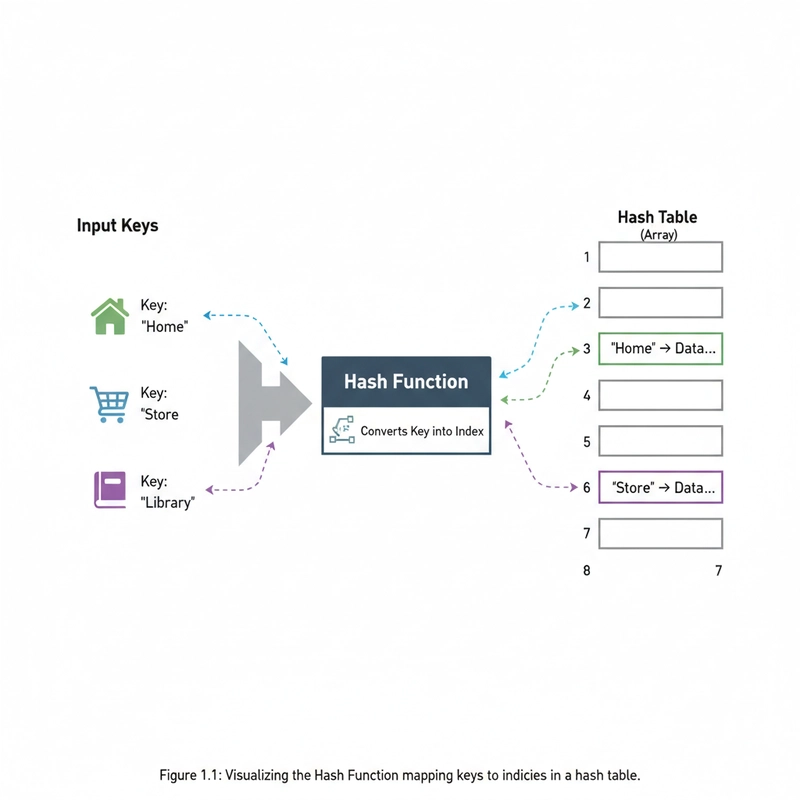
What is a Hash Function?
The Hash Function is the mathematical algorithm that performs the conversion. A good hash function is crucial for efficiency and should possess the following properties:
Here’s a visual representation of how a hash function maps keys to indices in a hash table:

The Challenge: Collisions
A collision occurs when two different keys hash to the same index in the hash table. Since the index space is smaller than the key space, collisions are unavoidable. Handling them efficiently is the central challenge in hashing.
2. Hashing Techniques: Collision Resolution
There are two primary strategies for resolving collisions:
2.1. Separate Chaining (Open Hashing)
In this technique, each bucket (index) in the hash table array holds a pointer to a linked list (or a similar dynamic structure, like a balanced binary search tree in modern Java).
- How it Works: When a collision occurs, the new key-value pair is simply added to the linked list at that index.
- Pros: Simple to implement, never runs out of space, and performance degrades gracefully as the load factor increases.
- Cons: Requires extra space for pointers, and traversing the linked list can degrade performance to O(N) in the worst case (where N is the number of elements).

2.2. Open Addressing (Closed Hashing)
In open addressing, all elements are stored directly within the hash table array itself. When a collision occurs, the algorithm probes(searches) for the next available empty slot.
Common probing techniques include:
-
Linear Probing: Searches the next slot sequentially:
index = (hash + i) (mod TableSize) -
Quadratic Probing: Searches slots at quadratic intervals:
index = (hash + i^2) (mod TableSize) -
Double Hashing: Uses a second hash function to determine the step size for probing.
-
Pros: Better cache performance (elements are stored contiguously), no need for external data structures (like linked lists).
-
Cons: Prone to clustering (groups of filled slots), requires careful load factor management, and deletion can be complex.
3. Hash Table and Hash Map: Clarified
A Hash Table is the generic data structure that implements the principle of hashing to store key-value pairs.
A Hash Map is an implementation of the Hash Table concept, typically referring to the specific class implementation in various programming languages (e.g., HashMap in Java).
Load Factor and Rehashing
The Load Factor (α) is a critical metric:
If the load factor gets too high (typically >0.75), collisions become frequent, and performance degrades. To maintain near O(1) performance, the Hash Table undergoes Rehashing (or resizing). This involves:
Creating a new, larger internal array (e.g., double the current size).
Iterating through all existing entries.
Re-calculating their hash codes and inserting them into the new, larger array. This process is an O(N) operation, which is why it’s done infrequently.
4. Hashing in Java: hashCode() and equals()
Java’s collection framework heavily relies on hashing, primarily through the java.util.Map interface and its implementing classes like HashMap.
The Java Hashing Contract
For any custom object to be used effectively as a key in a HashMap, it must correctly implement the hashCode() and equals() methods:
-
If two objects are equal according to the equals(Object) method, then calling the hashCode() method on each of the two objects must produce the same integer result.
-
If the hashCode() method produces the same integer result for two objects, they are NOT necessarily equal (this indicates a collision).
Example: If you override equals() without overriding hashCode(), a key inserted might hash to index ‘X’, but when you try to retrieve it later, the default hashCode() (which doesn’t consider the new equals() logic) might hash it to a different index ‘Y’, making the object “un-findable.”
Implementation Detail: Java 8+ Enhancement
In Java 8 and later, the internal structure of HashMap was improved. A single bucket that contains a very long linked list (due to numerous collisions, which degrades lookup to O(N)) is dynamically converted into a **Balanced Binary Search Tree (specifically a Red-Black Tree) **when the number of elements in the chain exceeds a certain threshold (usually 8). This upgrade improves the worst-case time complexity of lookup, insertion, and deletion from O(N) to O(logN).
5. Java’s Map Implementations: HashMap vs. Hashtable
While both classes implement the Map interface and use the hashing principle, they have key differences that dictate their use cases:
| Feature | HashMap (Recommended for modern code) | Hashtable (Legacy Class) |
|---|---|---|
| Synchronization | Non-synchronized (Not thread-safe) | Synchronized (Thread-safe) |
| Performance | Faster (No overhead of synchronization) | Slower (Synchronization overhead) |
| Nulls | Allows one null key and multiple null values | Does not allow null keys or null values |
| Iteration | Uses Iterator (Fail-Fast) | Uses Enumerator and Iterator (Enumerator is not Fail-Fast) |
| Inheritance | Extends AbstractMap | Extends Dictionary |
| Primary Use | Single-threaded environments, high-performance needs | Legacy code or when a simple, fully synchronized map is absolutely required |
Code Example: HashMap in Action
Here’s a basic Java code snippet demonstrating the use of HashMap:
Java
import java.util.HashMap;
import java.util.Map;
public class HashMapExample {
public static void main(String[] args) {
// Declaring a HashMap
Map studentScores = new HashMap<>();
// Adding key-value pairs
studentScores.put("Alice", 95);
studentScores.put("Bob", 88);
studentScores.put("Charlie", 92);
studentScores.put("David", 88); // David also has a score of 88
System.out.println("Student Scores: " + studentScores);
// Output: Student Scores: {Alice=95, Charlie=92, Bob=88, David=88} (Order not guaranteed)
// Getting a value
int bobScore = studentScores.get("Bob");
System.out.println("Bob's score: " + bobScore); // Output: Bob's score: 88
// Updating a value
studentScores.put("Alice", 97);
System.out.println("Alice's new score: " + studentScores.get("Alice")); // Output: Alice's new score: 97
// Checking if a key exists
boolean hasCharlie = studentScores.containsKey("Charlie");
System.out.println("Does Charlie exist? " + hasCharlie); // Output: Does Charlie exist? true
// Checking if a value exists
boolean hasScore90 = studentScores.containsValue(90);
System.out.println("Is there a student with score 90? " + hasScore90); // Output: Is there a student with score 90? false
// Removing a key-value pair
studentScores.remove("David");
System.out.println("Student Scores after removing David: " + studentScores);
// Output: Student Scores after removing David: {Alice=97, Charlie=92, Bob=88}
// Iterating through the HashMap
System.out.println("\nIterating through student scores:");
for (Map.Entry entry : studentScores.entrySet()) {
System.out.println(entry.getKey() + ": " + entry.getValue());
}
/*
Output:
Alice: 97
Charlie: 92
Bob: 88
*/
}
}
Code Example: Hashtable in Action
And here’s how you’d use a Hashtable. Notice the similar API but with the restrictions mentioned (no nulls) and its synchronized nature.
Java
import java.util.Hashtable;
import java.util.Map;
import java.util.Enumeration; // For legacy iteration
public class HashtableExample {
public static void main(String[] args) {
// Declaring a Hashtable
Hashtable capitalCities = new Hashtable<>();
// Adding key-value pairs
capitalCities.put("USA", "Washington D.C.");
capitalCities.put("France", "Paris");
capitalCities.put("Japan", "Tokyo");
capitalCities.put("Germany", "Berlin");
System.out.println("Capital Cities: " + capitalCities);
// Output: Capital Cities: {Japan=Tokyo, USA=Washington D.C., Germany=Berlin, France=Paris} (Order not guaranteed)
// Getting a value
String usaCapital = capitalCities.get("USA");
System.out.println("Capital of USA: " + usaCapital); // Output: Capital of USA: Washington D.C.
// Attempting to add a null key (will throw NullPointerException)
try {
// capitalCities.put(null, "Invalid");
} catch (NullPointerException e) {
System.out.println("Cannot add null key to Hashtable: " + e.getMessage());
}
// Attempting to add a null value (will throw NullPointerException)
try {
// capitalCities.put("Spain", null);
} catch (NullPointerException e) {
System.out.println("Cannot add null value to Hashtable: " + e.getMessage());
}
// Iterating through the Hashtable using Enumeration (legacy way)
System.out.println("\nIterating through capital cities (using Enumeration):");
Enumeration keys = capitalCities.keys();
while (keys.hasMoreElements()) {
String key = keys.nextElement();
System.out.println(key + ": " + capitalCities.get(key));
}
/*
Output:
Japan: Tokyo
USA: Washington D.C.
Germany: Berlin
France: Paris
*/
// Iterating through the Hashtable using Map.Entry (modern way, also works)
System.out.println("\nIterating through capital cities (using Map.Entry):");
for (Map.Entry entry : capitalCities.entrySet()) {
System.out.println(entry.getKey() + ": " + entry.getValue());
}
}
}
The Thread-Safe Alternative
For thread-safe operations in modern Java, the preferred choice is usually ConcurrentHashMap, which offers much higher performance and better concurrency than the legacy Hashtable by using a more granular locking mechanism.

