Relational databases are great at organizing structured data, but I’ve always found it a messy way to store multiple values as lists—like tags for blog posts or values from multiselect fields. The traditional approach means creating join tables, which basically requires intermediate tables linking records in many-to-many relationships.
Using Postgres arrays, you can store a list of values like ['news', 'tech', 'ai'] directly in a column. This keeps your schema cleaner and lets you write much simpler queries.
In this guide, I’ll show you how arrays can simplify your database design, how to query them with real SQL examples I’ve used, and when they actually improve performance in everyday projects.
Why Use Postgres Arrays in the First Place
Postgres arrays allow you to store multiple values in a single column, which is why they can be a powerful alternative to relational modeling. They are ideal for rapid prototyping and small-scale features like tags, checklists, or multiselect form inputs. In traditional database modeling, you have to create and manage multiple lookup and join tables. For example, to support tagging, you’d typically have a products table, a tags table, and a product_tags join table to associate multiple tags with each product. With Postgres arrays, you can represent related values directly in one field. This makes arrays particularly useful for quick prototyping and for simple lists that don’t require separate records with extra details.
Using arrays instead of normalized tables can lead to performance improvements. You avoid the overhead of join operations, extra indexes, and multitable queries. This is particularly useful in read-heavy applications that fetch entire records along with their associated attributes. Arrays also help keep your schema simple and easier to maintain. Not only is this useful for performance, but it also makes onboarding new developers faster.
Postgres arrays shine in practical scenarios where simplicity and speed matter. You can use them for product tagging, storing selected features or colors in a product catalog, or saving survey responses. In all these cases, arrays offer a straightforward and performant alternative to traditional many-to-many relationships. In the next sections, I’ll show you how arrays can simplify common scenarios like product tagging, helping you reduce complexity in both your database design and your queries.
Defining Array Columns in Postgres
When you use Postgres arrays, you work with actual data types, not just comma-separated strings. This gives you access to proper validation and powerful array operations that aren’t possible with plain text.
For example, text[] stores an array of strings, while integer[], boolean[], date[], and numeric[] restrict values to their respective types. This ensures consistency and prevents invalid data. You can even store structured content using jsonb[], which allows you to keep arrays of JSON objects in a single column.
You can define and populate array columns in Postgres using either the Supabase Table Editor or the SQL Editor. Using Supabase is the easier option: you can explore Postgres features right in the browser without installing or configuring anything locally.
Let’s walk through a real-life example. First, I’ll explain how to create a products table with a tags field using a Postgres text array. Based on this table, I’ll then show you how to insert rows with multiple tags and perform common operations like filtering, searching, and manipulating tag values using array functions.
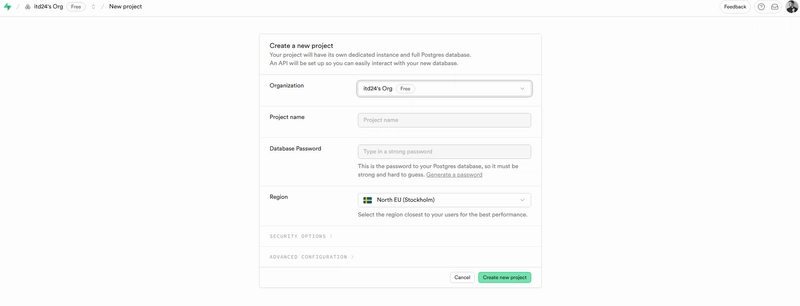
First, create a project in Supabase:

Open it, and choose between the Table Editor and SQL Editor to create and manage your tables:

In this case, use the SQL Editor to define a products table. Each product can have multiple tags, such as “organic”, “eco-friendly”, or “sale”, and multiple options, like color and size, which is stored in a JSONB[] array. Your table definition will look like this:
CREATE TABLE products (
id SERIAL PRIMARY KEY,
name TEXT NOT NULL,
description TEXT,
price NUMERIC(10, 2) NOT NULL,
tags TEXT[], -- Array of tags for product categorization
options JSONB[] -- Array of product options, like color and size
);
With this setup, you only need one table to store all relevant product data. You avoid joins and additional tables, keeping your schema simple and efficient.
Run the above query in the SQL editor to create your products table:

Inserting and Updating Array Data in Postgres
You can insert and update array data in Postgres using the ARRAY keyword. For example, if you want to add a T-shirt product to your products table with multiple tags, run the following in the Supabase SQL Editor:
INSERT INTO products (name, description, price, tags)
VALUES ('T-Shirt', 'Soft cotton T-shirt', 19.99, ARRAY['clothing', 'cotton', 'summer', 'men']);
After executing this, open the Table Editor to view your newly added row:

If you don’t specify a value for the array column, Postgres sets it to NULL by default. If you want to insert an empty array instead of a null value, you can do this:
INSERT INTO products (name, description, price, tags)
VALUES ('Mug', 'Ceramic coffee mug', 9.99, ARRAY[]::text[]);
This inserts a new row into your table:

Postgres correctly distinguishes between NULL and an empty array. If you try to query for tags = NULL, you’ll get no results because comparisons with NULL don’t behave the way they do with regular values.
You can also insert JSONB data into an array, just like other types. This is useful when storing flexible, structured items, such as per-user settings, third-party credentials, or service configurations. In your case, you can save store product options in a jsonb[] column. Just keep in mind that Postgres doesn’t enforce the structure of JSON values. So if you’re using this in a real-world application, you’ll need to handle validation at the application level:
INSERT INTO products (name, description, price, tags, options)
VALUES (
'Hat',
'Wide brim hat',
14.99,
ARRAY['clothing','men','winter'],
ARRAY[
'{"color":"white", "size":"M", "images":["http://www.image1.img","http://www.image2.img","http://www.image3.img"]}'::jsonb,
'{"color":"red", "size":"S", "images":[]}'::jsonb
]
);
With just a single INSERT, you save structured, multivalued data in one place. You did not need any extra joins or tables.
Efficiently Querying Arrays
You can query Postgres arrays in many ways using built-in operators and functions. For example, to find rows where the tags array exactly matches a specific sequence, you can run this query:
SELECT * FROM products WHERE tags = ARRAY['clothing','cotton','summer','men'];
It returns only one result:

That is because the array contents and order have to match exactly.
The “Contains” Operator
You can avoid such strict conditions if you use the “contains” operator (@>) to check if an array contains certain elements:
SELECT * FROM products WHERE tags @> ARRAY['men','summer'];
This query returns all rows where both “men” and “summer” exist within the tags array, regardless of order:

The “Is Contained By” Operator
You can also reverse the logic using the “is contained by” operator (<@) to find rows where the entire tags array is a subset of another array:
SELECT * FROM products WHERE tags <@ ARRAY['clothing','cotton','men','summer'];
Since an empty array is considered a subset of any array, using the <@ operator will always include rows where the compared array is empty. That’s why the above query returns two rows:
This is especially useful when searching for simpler or narrower tag combinations. For example, you could search ['winter', 'clothes'] to find all clothes suited for the colder months of the year.
Using the “Overlaps” Operator
If you only care whether at least one matching tag exists, such as searching for clothes suited for either winter or summer, use the “overlaps” (&&) operator:
SELECT * FROM products WHERE tags && ARRAY['clothing','men'];
This will return any row that contains “clothing”, “men”, or both:

The Cardinality Function
To identify empty arrays, use the cardinality function. This function returns the number of elements in an array:
SELECT * FROM products WHERE CARDINALITY(tags) = 0;
This helps you find products without any tags:

Since arrays in Postgres are ordered and 1-indexed, you can also query specific positions:
SELECT * FROM products WHERE tags[2] = 'cotton';
This returns rows where the second element in the tags array is exactly “cotton”:

You can also use arrays as search parameters with the ANY and ALL keywords. Use ANY to check if at least one value satisfies a condition:
SELECT * FROM products WHERE price = ANY(ARRAY[9.99,14.99]);
This fetches products priced at either 9.99 or 14.99:

Use ALL to apply a condition across all values in the array:
SELECT * FROM products WHERE price > ALL(ARRAY[9.99,5.99]);
This returns products priced higher than every value in the array:

Those are just some of the array operators and keywords you can use to unlock the full potential of arrays in your Postgres queries.
Modifying Arrays in Postgres
After learning how to use arrays in search queries, the next step is understanding how to update the array values themselves. For example, you might want to add or remove a tag from a specific product over time. With Postgres, you can modify arrays with simple and expressive SQL functions.
Using array_append, array_prepend, and array_remove
If you want to add a new value to an existing array—for example, a new tag to one of your products—you can use array_append:
UPDATE products
SET tags = array_append(tags, 'fabric')
WHERE id = 1;
This adds fabric to the end of the tags array:

To add a value to the beginning instead, use array_prepend:
UPDATE products
SET tags = array_prepend('fabric', tags)
WHERE id = 1;
This query adds a tag to the beginning of the array:

To remove a specific element from the array, you can call array_remove:
UPDATE products
SET tags = array_remove(tags, 'fabric')
WHERE id = 1;
This SQL removed all fabric tags in the array:

array_append, array_prepend, and array_remove return a new array, which is why you had to assign the result to the tags column.
The Concatenation Operator
When working with tags, you will rarely want to add just one at a time. If you need to add multiple tags at once, use the array concatenation operator ||:
UPDATE products
SET tags = tags || ARRAY['fabric', 'colored']
WHERE id = 1;
This appends all values from the new array to the existing one:

Using array_position
To find an item in a Postgres array, use array_position. It returns the index of the first match starting at 1 since Postgres arrays are 1-based:
SELECT array_position(tags, 'summer') FROM products WHERE id = 1;
Executing the above query gets you the index of the tag “summer”:

If the tag you search for does not exist in the array, you get NULL as a result.
The array_replace Function
Sometimes you may need to replace a value in a Postgres array. For example, if you want to change a product’s tag from “summer” to “winter” to recategorize it, you can use the function array_replace:
UPDATE products
SET tags = array_replace(tags, 'summer', 'winter')
WHERE id = 1;
With this change, your product is now tagged for winter instead of summer:

Combine these tools so you can efficiently manage and transform array data in Postgres with clear and readable SQL.
Advanced Array Operations: Filtering, Sorting, and Aggregating
Sometimes it’s not enough to store or update arrays. You might also need to work with the values inside them. Postgres provides functions to filter, sort, or analyze array elements.
The unnest Function
For simple analytics, having one row per array item can be very helpful. To break arrays into individual elements, use the unnest() function. For example, you can run the following query to list all tags for a product with id = 1 :
SELECT id, UNNEST(tags) FROM products WHERE id = 1;
This query returns one row per tag, showing each tag separately for that product.

This is especially useful for analytics. Suppose you want to count how many products use each tag. You can unnest all tags, group them, and count:
SELECT tag, COUNT(*) FROM (
SELECT unnest(tags) AS tag FROM products
) AS sub
GROUP BY tag;
This query gives you a list of tags along with the number of products that include each one:

This helps you quickly identify the most popular tags.
Using array_agg for Aggregation
To combine values into a single array, use the array_agg() function. To explain this function, let’s take another real-life example that can show it better than our products table could. Suppose we have a students table where each student has chosen a subject. The table would consist of two columns—name and subject. If you want to aggregate the names of all students who have the subject “math” associated with them, you can use the function array_agg():
SELECT array_agg(name) FROM students WHERE subject = 'math';
This returns a single row containing an array of all students who have chosen “math”:

You can combine array_agg() with GROUP BY to rebuild arrays from grouped rows, allowing you to pivot, reformat, or aggregate your data as needed.
Using jsonb_array_elements_text
If you’re working with a jsonb array instead of a native Postgres array, you can extract each value using jsonb_array_elements_text():
SELECT jsonb_array_elements_text('["fruit", "organic", "local"]'::jsonb);
This returns one row per JSON array element, which is perfect for hybrid JSON-array structures.
Best Practices for Using Postgres Arrays
While Postgres arrays work well for simple lists like tags or flags, you should avoid them when dealing with many-to-many relationships that include metadata.
For example, if you want to assign categories to products and each category may carry additional information or must be unique, you should use a separate categories table and a join table to connect products with their categories. Arrays can’t reference foreign keys, so you lose referential integrity and the ability to enforce constraints.
When Not to Use Postgres Arrays
Though it may seem counterintuitive, one of the best practices you can adopt is knowing when not to use arrays. You might feel tempted to use arrays for many-to-many links, but doing so breaks database normalization. While arrays can be indexed with the Generalized Inverted Index (GIN) for fast searches, they don’t support constraints, can’t store extra info like timestamps or statuses for each item, and aren’t as flexible as proper join tables.
For instance, if you store user roles in an array within a users table, it becomes difficult to associate each role with important contextual data.
In these cases, just stick with proper relational tables and joins. They give you flexibility, integrity, and maintainability.
Indexing Arrays in Postgres with GIN Indexes
When you store arrays in a Postgres column, like you did in the above examples with tags TEXT[], you need to think about how you’ll efficiently query them. Searching through large data sets can get slow. Luckily, Postgres also has a solution for that use case. You can speed things up by adding a GIN index.
GIN indexes work well with composite types like arrays, JSONB, or full-text search vectors by indexing each array element individually rather than the entire row. For example, if you create a GIN index, you’ll see a significant speedup:
CREATE INDEX idx_tags_gin ON products USING GIN(tags);
This allows Postgres to quickly locate rows where the array contains a specific value, like in the following query:
SELECT * FROM products WHERE 'clothing' = ANY(tags);
Keep in mind that you’ll only see the real benefits of GIN indexes with larger data sets. If your table has just a few thousand rows, you won’t notice much of a performance difference compared to a nonindexed search. Postgres can scan the entire table so quickly that using an index wouldn’t save time. You’ll start to see measurable improvements when working with tens or hundreds of thousands of rows.
This setup allows you to scan arrays much more efficiently, especially when filtering by individual values.
Validation Considerations
Besides performance, you also need to enforce data integrity. Postgres gives you tools to validate arrays directly in your schema. For example, if you want to allow only up to five tags per product, you can define a CHECK constraint:
CHECK (array_length(tags, 1) <= 5)
Postgres already enforces the array’s data type, but you can restrict the allowed values even further using containment checks. Below is an example:
CHECK (tags <@ ARRAY['clothing', 'winter', 'fabric'])
This makes sure that only predefined tags are accepted.
If you combine GIN indexing for performance and table constraints for validation, you keep your array data both fast and reliable.
Conclusion
In this article, you’ve seen how Postgres arrays can simplify your database design and make your queries more efficient. Arrays let you store related values in a single column—like tags, flags, or options—without the overhead of extra join tables. This can help you get simpler schemas, fewer joins, and often, faster reads. This is especially true when combined with GIN indexing. You also learned how to manipulate arrays with functions like array_append, array_remove, and array_replace; how to flatten them with unnest() for aggregation; and how to enforce validation to maintain clean, consistent data.
That said, arrays aren’t a silver bullet. Use them when you need simple lists that don’t require additional metadata or relational integrity. But if your data involves many-to-many relationships with extra attributes, like timestamps or roles with permissions, you’ll still want to reach for traditional relational modeling.