
AWS Glue is an AWS service that helps discover, prepare, and integrate all your data at any scale. It can aid in the process of transformation, discovering, and integrating data from multiple sources.
In this blog we have a data source that uploads JSON data files periodically to an Amazon S3 bucket named ‘uploads-bucket’. These JSON data files contain log entries.
Below is an example of one of the log entries JSON files that are being uploaded to the Amazon S3 bucket named uploads-bucket.
{
"timestamp": "2025-10-04T10:15:30Z",
"level": "ERROR",
"service": "authentication",
"message": "Failed login attempt",
"user": {
"id": "4626",
"username": "johndoe",
"ip_address": "192.168.1.101"
},
"metadata": {
"session_id": "abc123xyz",
"location": "Kathmandu"
}
}
Step 1: Create the processing Lambda Function
Now, we will implement an AWS Lambda function that processes Amazon S3 object-created events for the JSON files and the Lambda code will transform the data and write it to a second Amazon S3 bucket named
target-bucket. This function will:
- Transform the JSON data.
- Write it to a target S3 bucket named target-bucket in Parquet format.
- Catalog the data in AWS Glue for querying.
import json
import boto3
import awswrangler as wr
import pandas as pd
GLUE_DATABASE = "log_database"
TARGET_BUCKET = "target-bucket"
def parse_event(event):
# EventBridge S3 object-created structure
key = event['detail']['object']['key']
bucket = event['detail']['bucket']['name']
return key, bucket
def read_object(bucket, key):
s3 = boto3.resource('s3')
obj = s3.Object(bucket, key)
return obj.get()['Body'].read().decode('utf-8')
def create_database():
databases = wr.catalog.databases()
if GLUE_DATABASE not in databases['Name'].values:
wr.catalog.create_database(GLUE_DATABASE)
print(f"Database {GLUE_DATABASE} created")
else:
print(f"Database {GLUE_DATABASE} already exists")
def lambda_handler(event, context):
key, bucket = parse_event(event)
object_body = read_object(bucket, key)
create_database()
log_entry = json.loads(object_body)
# Flatten JSON
log_df = pd.json_normalize(log_entry)
# Create partition columns for Glue
log_df['log_level'] = log_df['level']
log_df['service_name'] = log_df['service']
# Write logs to Glue catalog
wr.s3.to_parquet(
df=log_df.astype(str),
path=f"s3://{TARGET_BUCKET}/data/logs/",
dataset=True,
database=GLUE_DATABASE,
table="logs",
mode="append",
partition_cols=["log_level", "service_name"],
description="Application log table",
parameters={
"source": "Application",
"class": "log"
},
columns_comments={
"timestamp": "Time of the log event",
"level": "Log level (INFO, WARN, ERROR, etc.)",
"service": "Service generating the log",
"message": "Log message",
"user.id": "User identifier",
"user.username": "Username"
}
)
We need to attach the necessary permission role to the Lambda function. The function needs access to both the S3 bucket and AWS Glue.
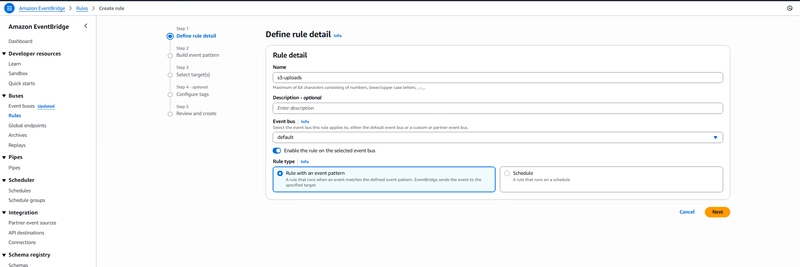
Step 2:Creating an Amazon EventBridge Rule
Now we will create an Amazon EventBridge rule to invoke our AWS Lambda function when an object is uploaded to the Amazon S3 bucket. We will create a new Amazon EventBridge rule as follows:
- Name: s3-uploads
- Event bus: default
- Rule type: Rule with an event pattern

Scroll down to the Event pattern section, and enter and select:
- Event source: AWS Services
- AWS service: S3
- Event type: Object Created
- Specific Bucket: uploads-bucket

Target Configuration:
- Target types: AWS Lambda
- Function: Enter our Lambda function name

The event pattern JSON here will be:
{
"source": ["aws.s3"],
"detail-type": ["Object Created"],
"detail": {
"bucket": {
"name": ["uploads-bucket"]
}
}
}
Step 3: Add index partition to the logs table using AWS Glue
When the Lambda function we created runs, it will create tables named ‘logs table’ in the Glue Database.
In the AWS Console, go to the Glue dashboard.
- To see databases, in the left-hand menu, under Data Catalog, click Databases. We will find the database our Lambda function created on this section. Click on this database.
- Click on the logs table. The table data is stored in the target Amazon S3 bucket named target-bucket.
- We will now add a partition index in this table for faster query performance.
- To begin creating an index, click Add index
- Enter and select the following to configure the index
Index name: log_level_index
Index keys: log_level
Click Update - Now we can also view this data using Amazon Athena. For this, there is an option at the top of the page , where we need to click on Actions and then View Data.
Step 4: Searching within your Indexed AWS S3 data
With index now in place, we can query efficiently using log_level as filter.
We need to first open the Athena console and open the query editor and select our database.
Example query: Retrieve all ERROR logs from the authentication service:
SELECT timestamp, service, message, user_username, metadata_location
FROM logs
WHERE log_level="ERROR"
AND service_name="authentication";
In conclusion, we can combine AWS Lambda, Amazon S3, AWS Glue, and Athena, to build a fully serverless, scalable data pipeline that transforms, catalogs, and queries e-commerce data in near real-time. We can also leverage Glue partitions and indexes for allows for efficient storage and faster analytics, with Athena enabling ad-hoc queries without the overhead of managing traditional databases.

